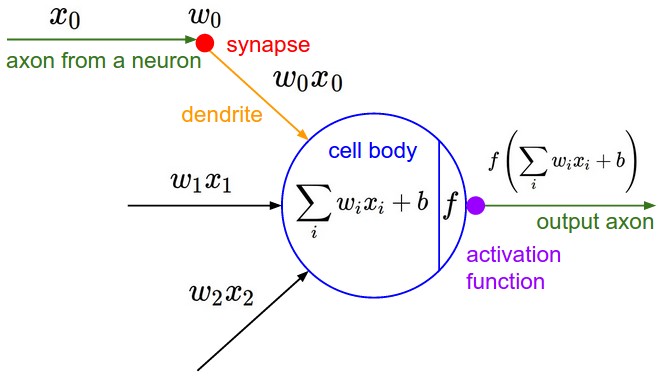
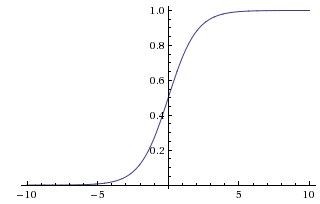
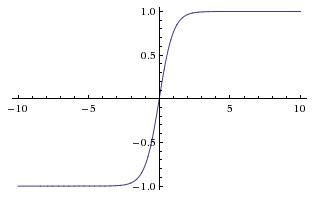
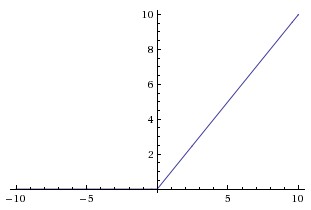
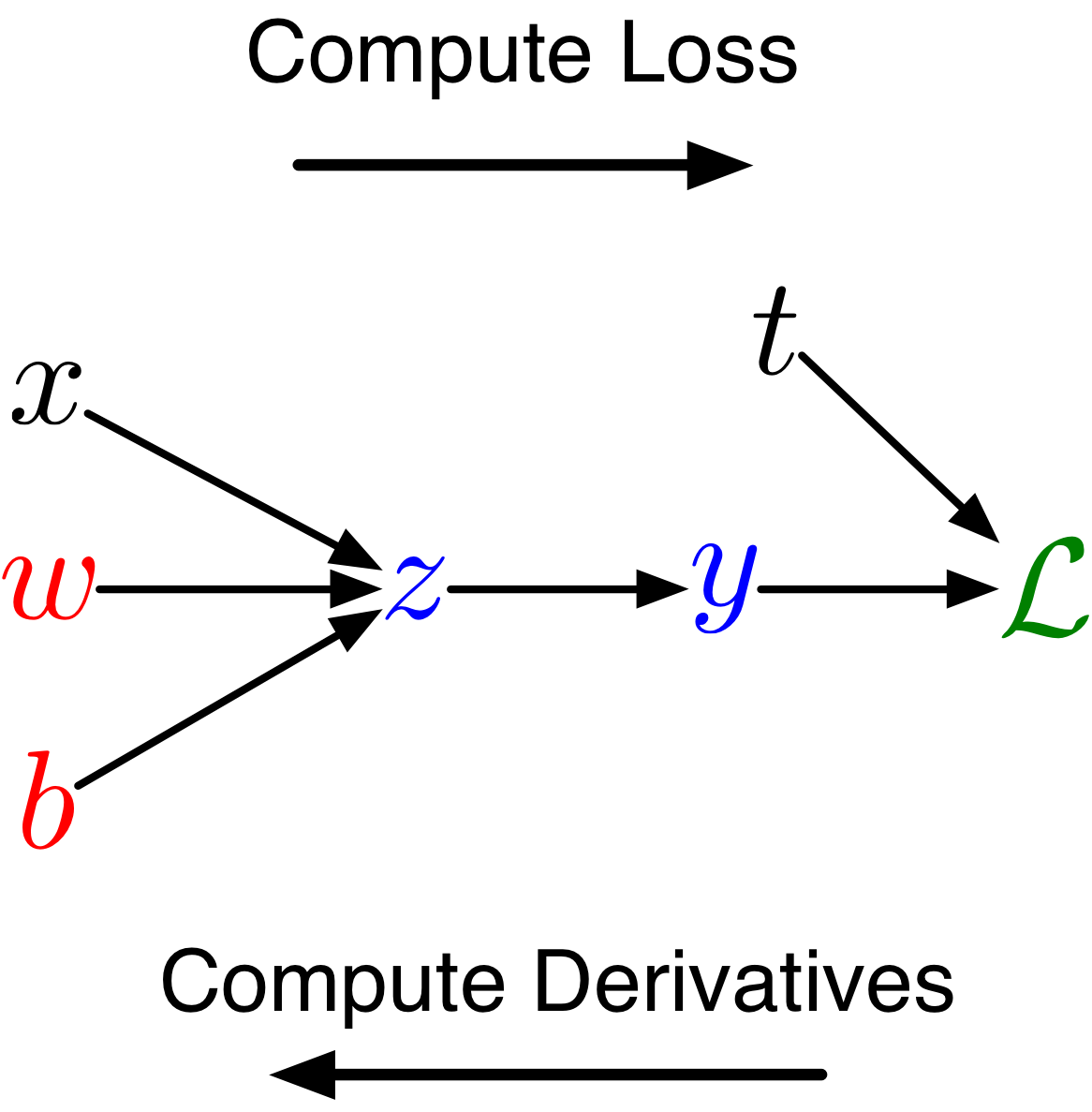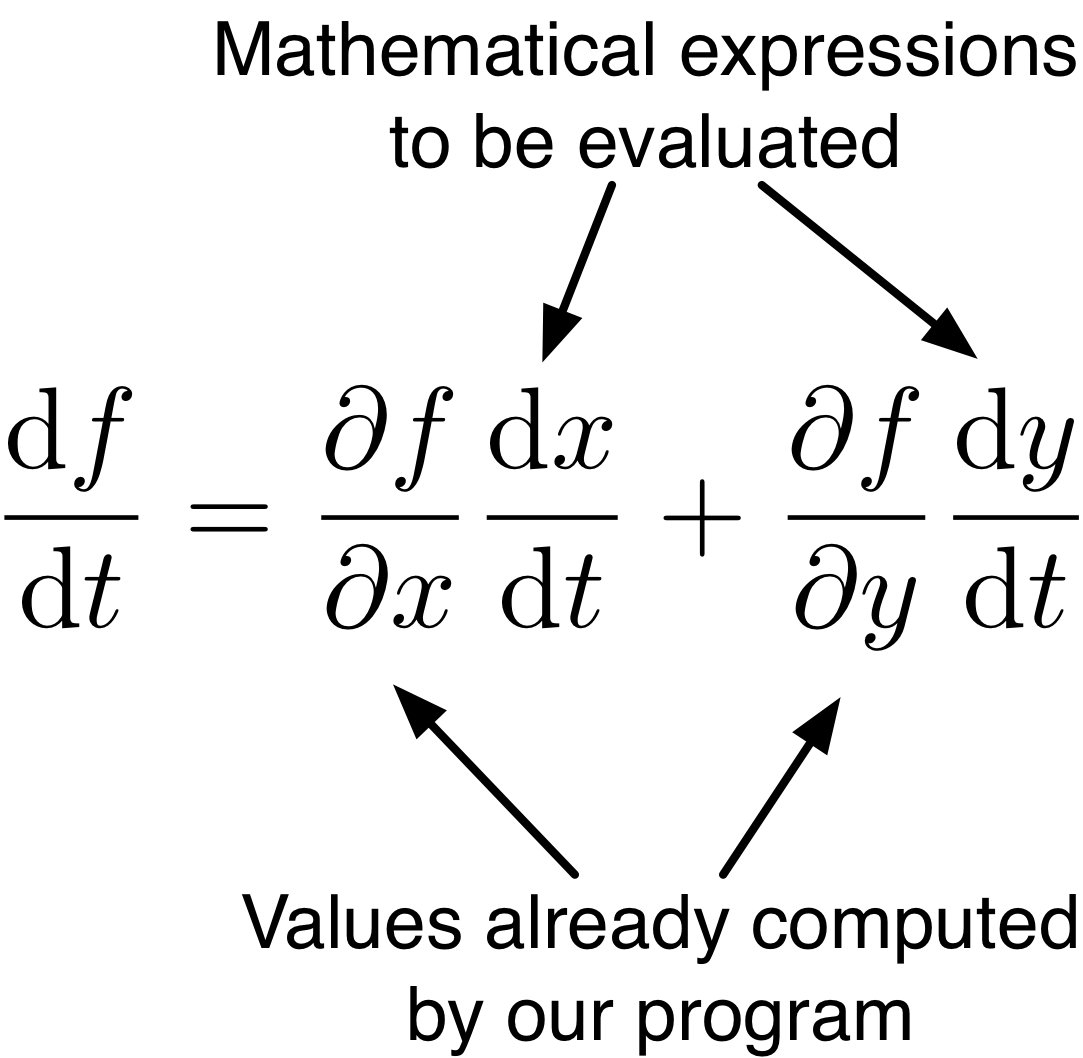A binary linear classifier divides the euclidean space into two half-spaces
Half-spaces are convex
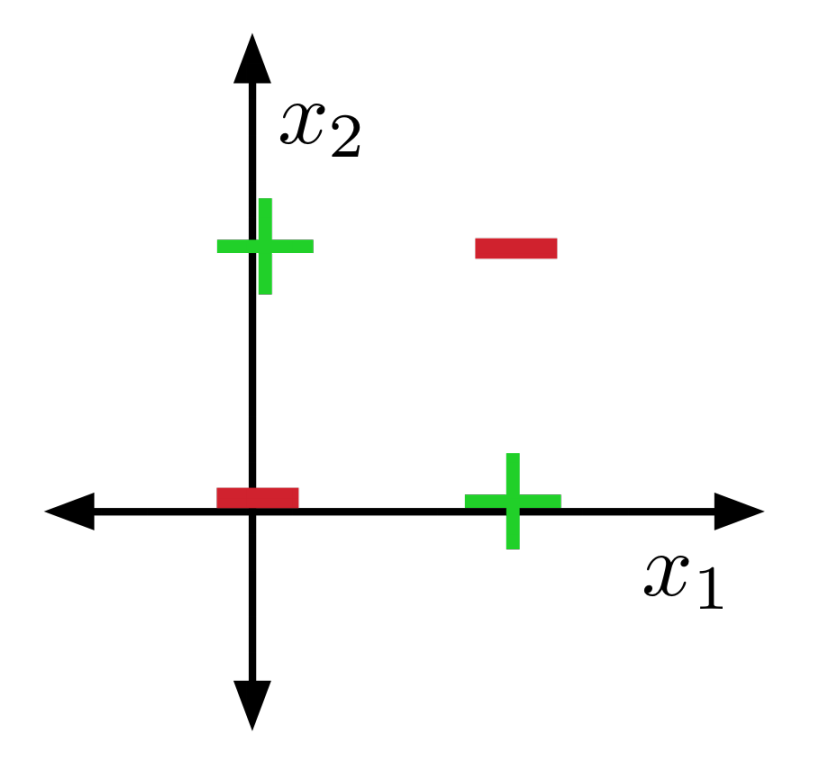
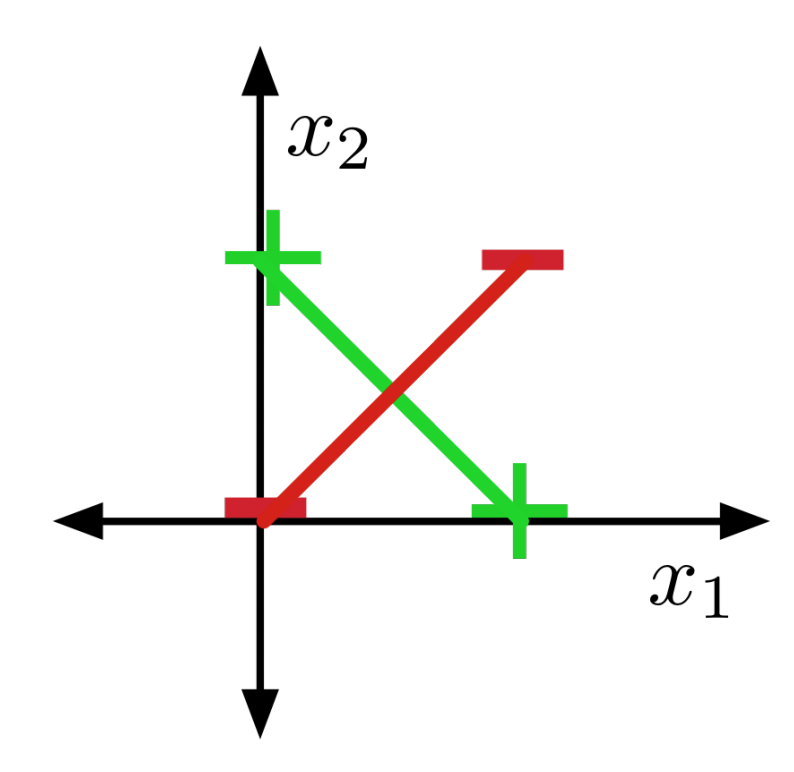
XOR not linearly separable II
Suppose there were some feasible hypothesis. If the positive examples are in the positive half-space, then the green line segment must be as well.
Similarly, red line segment must lie within the negative half-space.
But the intersection can’t lie in both half-spaces. Contradiction!
History of the XOR Example
Minsky and Papert shown in their work Perceptrons that XOR cannot be learned by a Neuron.
Its pessimistic outlook on perceptrons is assumed as one of the causes for the AI winter of the 70s / early 80s.
A more troubling example
These images represent 16-dimensional vectors. Want to distinguish patterns A and B in all possible translations (with wrap-around).
Suppose there’s a feasible solution. The average of all translations of A is the vector (0.25, 0.25, . . . , 0.25). Therefore, this point must be classified as A. All translations of B have the same average. Contradiction!
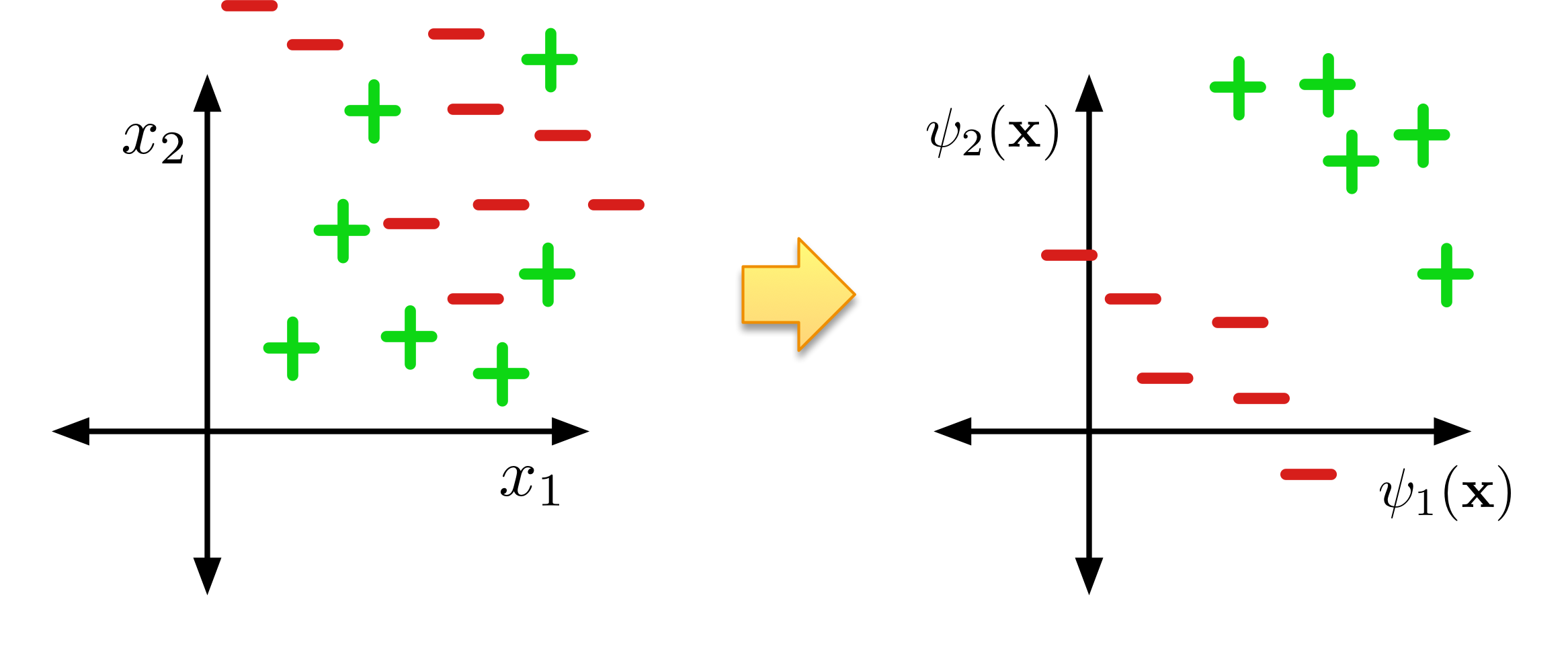
(Nonlinear) Feature Maps
Sometimes, we can overcome this limitation with nonlinear feature maps.
Nonlinear feature maps transform the original input features into a different (often higher dimensional) representation.
Consider the XOR problem again and use the following feature map: \[\Psi({\bf x}) = \begin{pmatrix}x_1 \\ x_2 \\ x_1x_2 \end{pmatrix}\]
(Nonlinear) Feature Maps II
\(x_1\)
\(x_2\)
\(\phi_1({\bf x})\)
\(\phi_2({\bf x})\)
\(\phi_3({\bf x})\)
t
0
0
0
0
0
0
0
1
0
1
0
1
1
0
1
0
0
1
1
1
1
1
1
0
This is linearly separable (Try it!)
… but generally, it can be hard to pick good basis functions.
We’ll use neural nets to learn nonlinear hypotheses directly
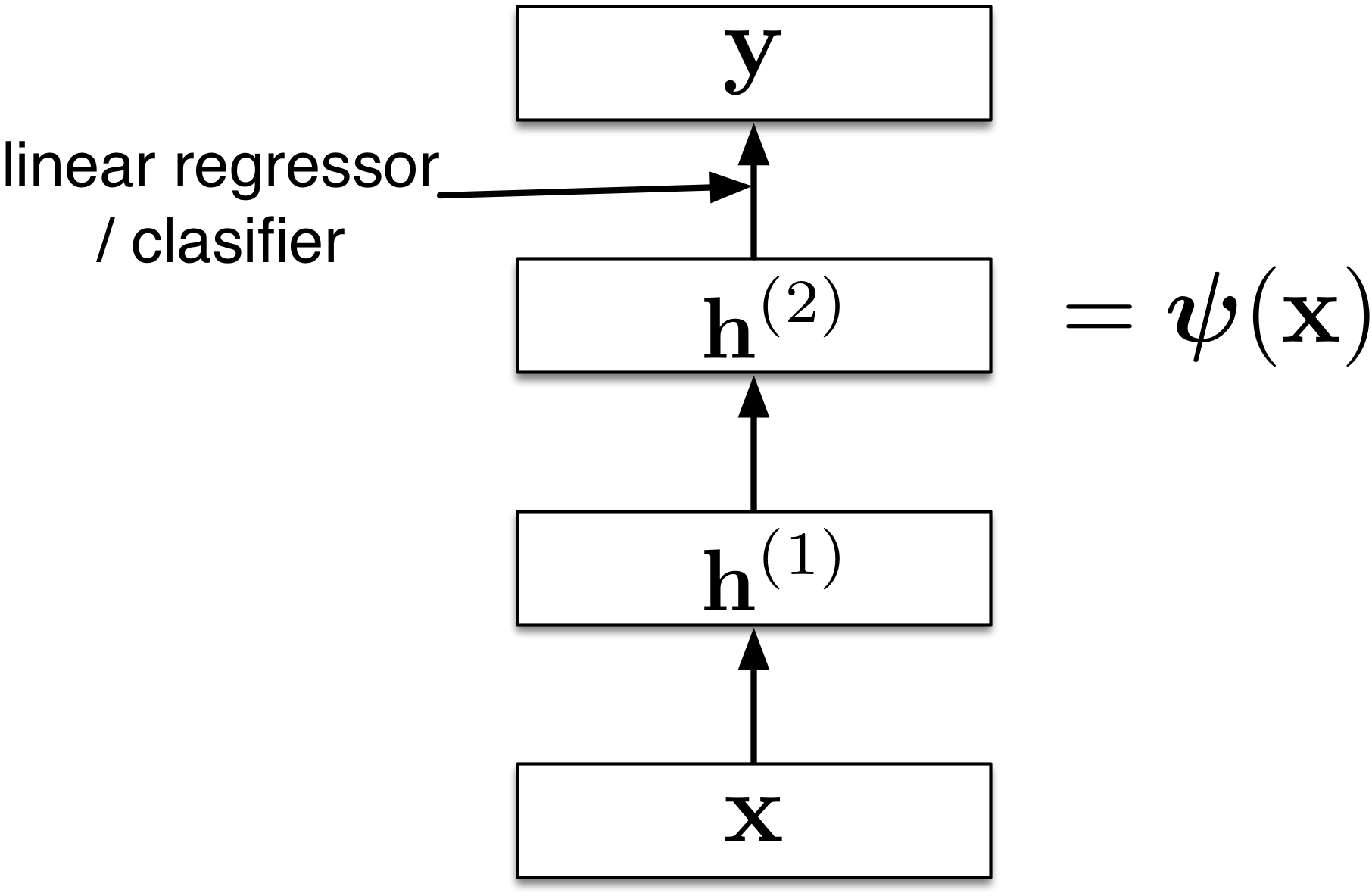
Multilayer Perceptrons
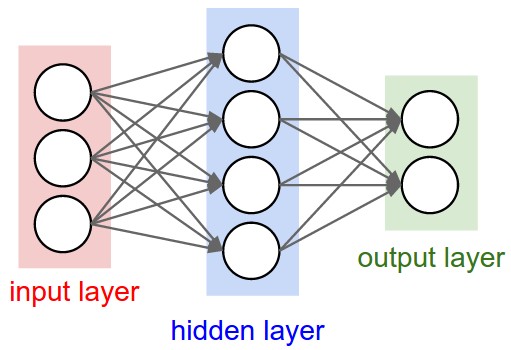
An Artificial Neural Network (Multilayer Perceptron)
Idea
Use a simplified (mathematical) model of a neuron as building blocks
Connect the neurons together accross multiple layers.
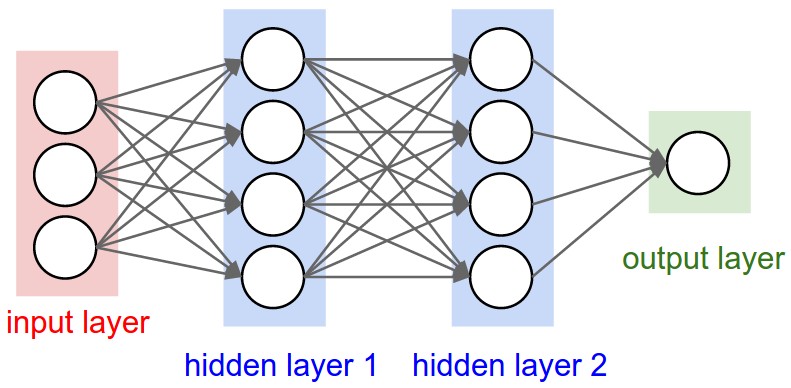
An Artificial Neural Network (Multilayer Perceptron) II
An input layer: feed in input features (e.g. like retinal cells in your eyes)
A number of hidden layers: don’t have specific meaning
An output layer: interpret output like a “grandmother cell”
But what do these neurons mean?
Use \(x_i\) to encode the input
e.g. pixels in an image
Use \(y\) to encode the output (of a binary classification problem)
e.g. cancer vs. not cancer
Use \(h_i^{(k)}\) to denote a unit in the hidden layer
Multilayer feed-forward neural nets with nonlinear activation functions are universal approximators: they can approximate any function arbitrarily well.
This has been shown for various activation functions (thresholds, logistic, ReLU, etc.)
Even though ReLU is “almost” linear, it’s nonlinear enough!
Universality for binary inputs and targets
Hard threshold hidden units, linear output
Strategy: \(2^D\) hidden units, each of which responds to one particular input configuration
Only requires one hidden layer, though it needs to be extremely wide!
Limits of universality
You may need to represent an exponentially large network.
If you can learn any function, you might just overfit.
Backpropagation
Training Neural Networks
How do we find good weights for the neural network?
We can continue to use the loss functions:
cross-entropy loss for classification
square loss for regression
The neural network operations we used (weights, etc) are (almost everywhere) differentiable
We can use gradient descent!
Gradient Descent Recap
Goal: Compute the minimum of a function \(\mathcal{E}({\bf a})\)
Start with a set of parameters \(\mathbf{a}_0\) (initialize to some value)
Compute the gradient \(\frac{\partial \mathcal{E}}{\partial \mathbf{a}}\).
Update the parameters towards the negative direction of the gradient
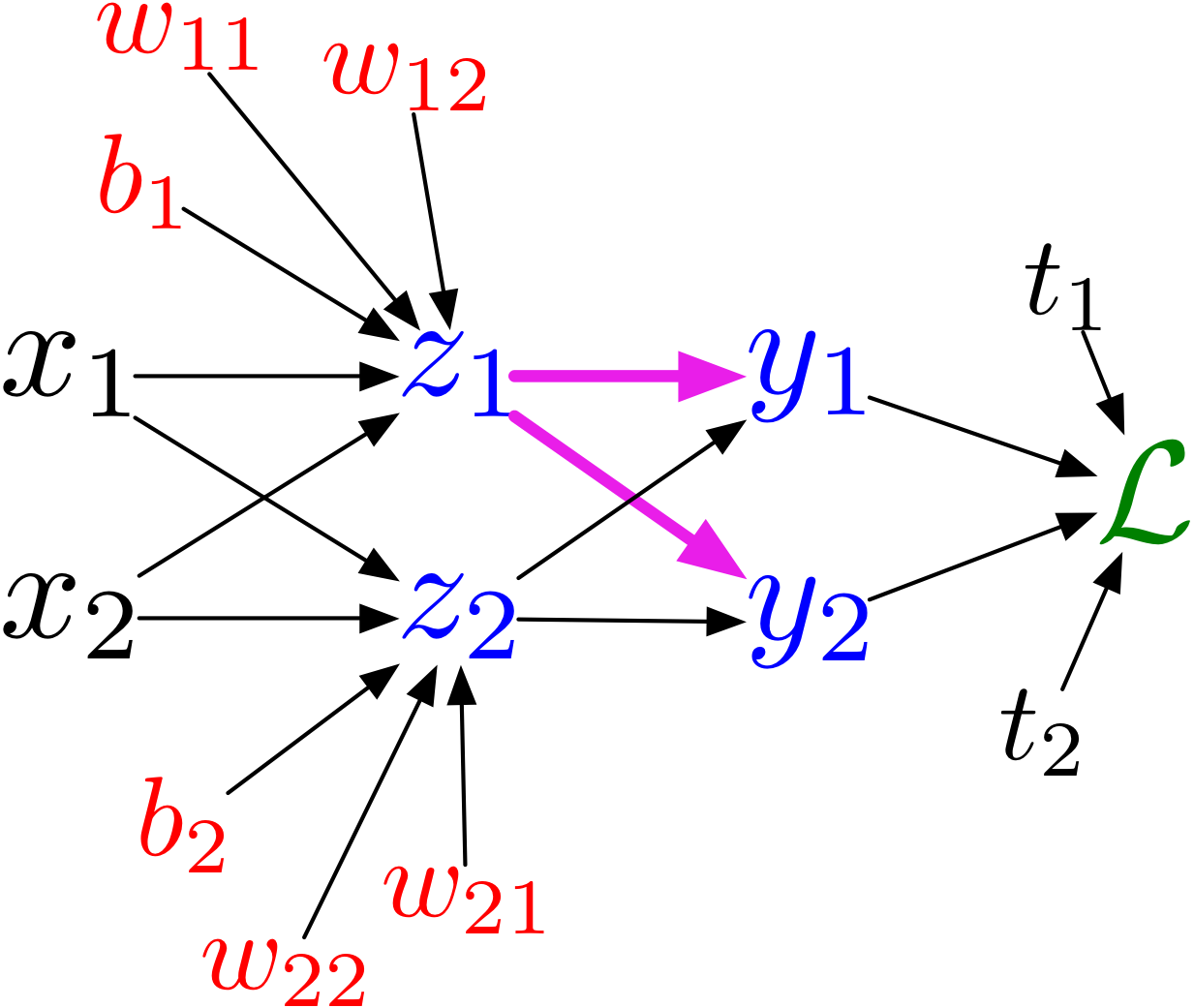
Gradient Descent for Neural Networks
Idea: Use gradient descent for “learning” neural networks.
We have a lot of parameters
High dimensional (all weights and biases are parameters)
Hard to visualize
Many iterations (“steps”) needed
In Deep Learning \(\frac{\partial \mathcal{E}}{\partial w}\) is the average of \(\frac{\partial \mathcal{L}}{\partial w}\) over multiple training examples
Challenge: How to compute \(\frac{\partial \mathcal{L}}{\partial w}\) effectively.
Solution: Backpropagation!
Univariate Chain Rule
Recall: if \(f(x)\) and \(x(t)\) are univariate functions, then
Univariate Chain Rule for Least Squares with a Logistic Model
Recall: Univariate logistic least squares model
\[\begin{align*}
z &= wx + b \\
y &= \sigma(z) \\
\mathcal{L} &= \frac{1}{2}(y - t)^2
\end{align*}\]
Let’s compute the loss derivative
Univariate Chain Rule Computation I
How you would have done it in calculus class
\[\begin{align*}
\mathcal{L} &= \frac{1}{2} ( \sigma(w x + b) - t)^2 \\
\frac{\partial \mathcal{L}}{\partial w} &= \frac{\partial}{\partial w} \left[ \frac{1}{2} ( \sigma(w x + b) - t)^2 \right] \\
&= \frac{1}{2} \frac{\partial}{\partial w} ( \sigma(w x + b) - t)^2 \\
&= (\sigma(w x + b) - t) \frac{\partial}{\partial w} (\sigma(w x + b) - t) \\
&\ldots
\end{align*}\]
Univariate Chain Rule Computation II
How you would have done it in calculus class
\[\begin{align*}
\ldots &= (\sigma(w x + b) - t) \frac{\partial}{\partial w} (\sigma(w x + b) - t) \\
&= (\sigma(w x + b) - t) \sigma^\prime (w x + b) \frac{\partial}{\partial w} (w x + b) \\
&= (\sigma(w x + b) - t) \sigma^\prime (w x + b) x
\end{align*}\]
Univariate Chain Rule Computation III
Similarly for \(\frac{\partial \mathcal{L}}{\partial b}\)
\[\begin{align*}
\mathcal{L} &= \frac{1}{2} ( \sigma(w x + b) - t)^2 \\
\frac{\partial \mathcal{L}}{\partial b} &= \frac{\partial}{\partial b} \left[ \frac{1}{2} ( \sigma(w x + b) - t)^2 \right] \\
&= \frac{1}{2} \frac{\partial}{\partial b} ( \sigma(w x + b) - t)^2 \\
&= (\sigma(w x + b) - t) \frac{\partial}{\partial b} (\sigma(w x + b) - t) \\
&\ldots
\end{align*}\]
Univariate Chain Rule Computation IV
Similarly for \(\frac{\partial \mathcal{L}}{\partial b}\)
\[\begin{align*}
\ldots &= (\sigma(w x + b) - t) \frac{\partial}{\partial b} (\sigma(w x + b) - t) \\
&= (\sigma(w x + b) - t) \sigma^\prime (w x + b) \frac{\partial}{\partial b} (w x + b) \\
&= (\sigma(w x + b) - t) \sigma^\prime (w x + b)
\end{align*}\]
Q: What are the disadvantages of this approach?
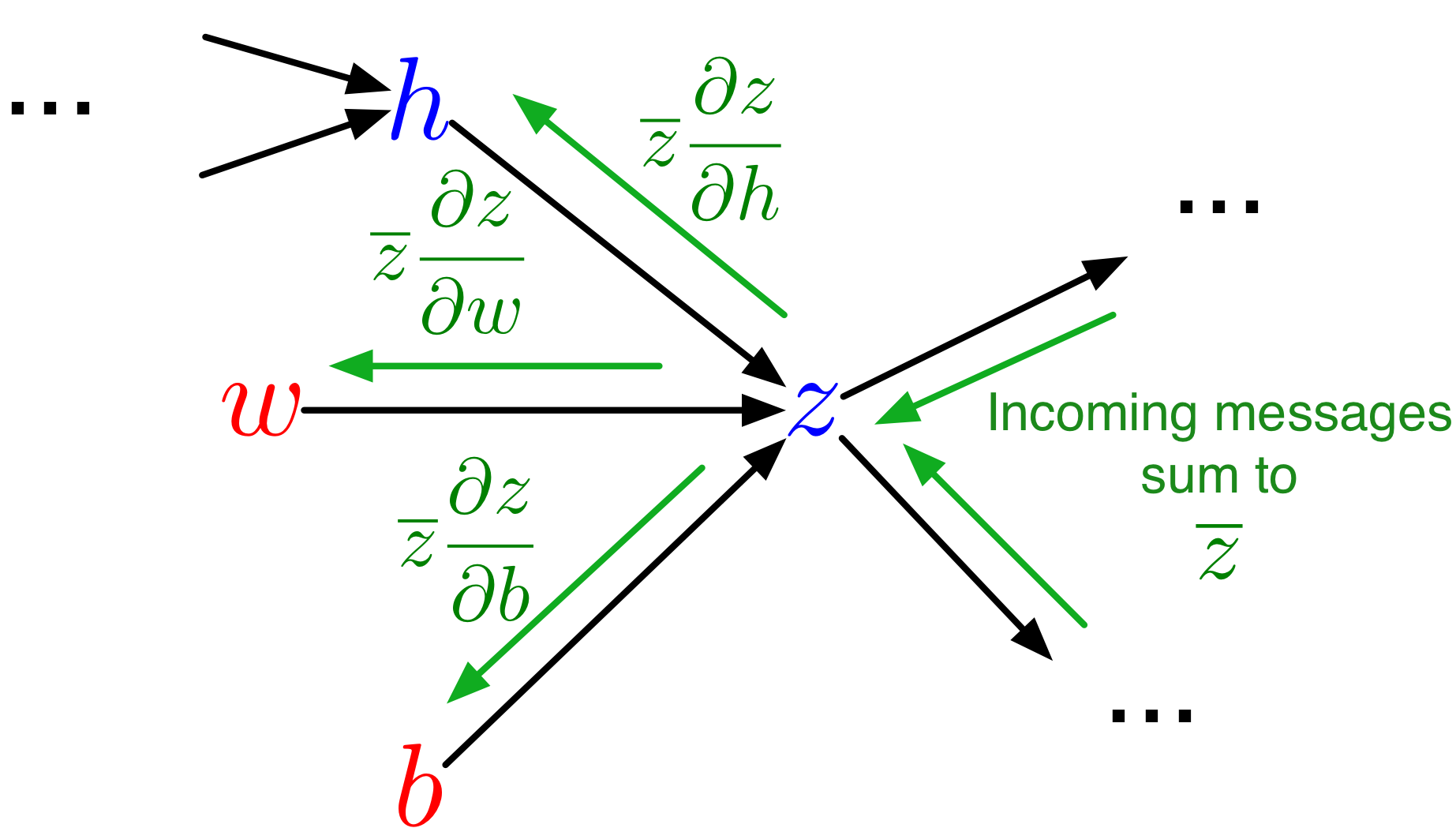
A More Structured Way to Compute the Derivatives
\[\begin{align*}
z &= wx + b \\
y &= \sigma(z) \\
\mathcal{L} &= \frac{1}{2}(y - t)^2
\end{align*}\]
Less repeated work; easier to write a program to efficiently compute derivatives
A More Structured Way to Compute the Derivatives II