CSC413 Neural Networks and Deep Learning
Lecture 4
Computer vision is hard


Computer vision is really hard

How can you “hard code” an algorithm that still recognizes that this is a cat?
Working with Small Images
In the week 3 tutorial, we worked with small, MNIST images, which are \(28 \times 28\) pixels, black and white.
How do our models work?
Notebook Demo - Logistic Regression Weights

Notebook Demo - MLP Weights (first layer)

Biological Influence
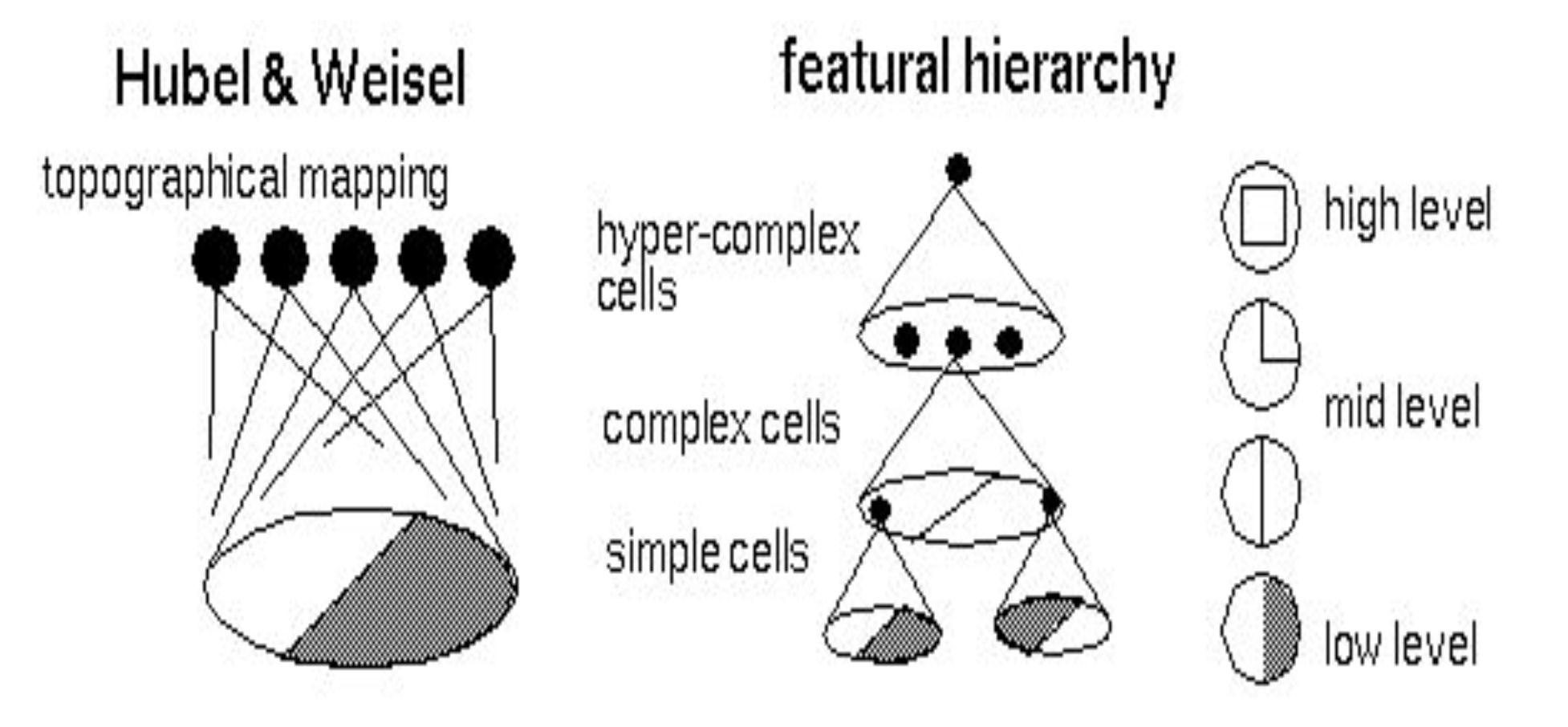
There is evidence that biological neurons in the visual cortex have locally-connected connections
See Hubel and Wiesel Cat Experiment (Note: there is an anesthetised cat in the video that some may find disturbing).
Locally Connected Layers
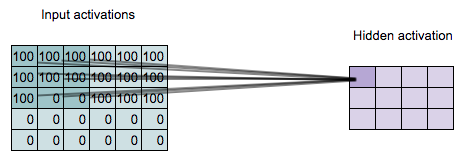
Each hidden unit connects to a small region of the input (in this case a \(3 \times 3\) region)
Locally Connected Layers
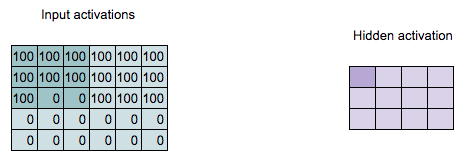 (Remove lines for readability)
(Remove lines for readability)
Locally Connected Layers
Hidden unit geometry has a 2D geometry consistent with the input.
Locally Connected Layers

Locally Connected Layers
Locally Connected Layers

Locally Connected Layers
Locally Connected Layers
Q: Which region of the input is this hidden unit connected to?
Locally Connected Layers
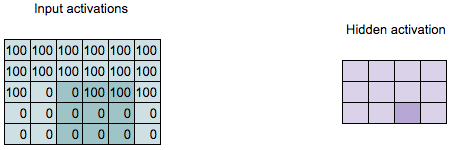
Summary
Fully-connected layers:
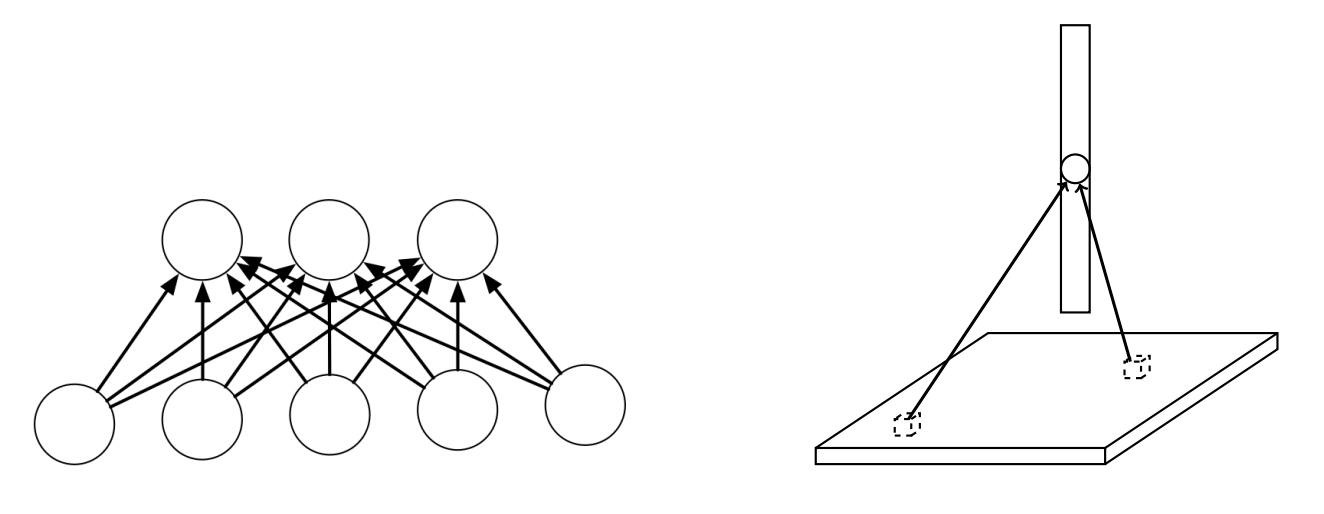
Locally connected layers:
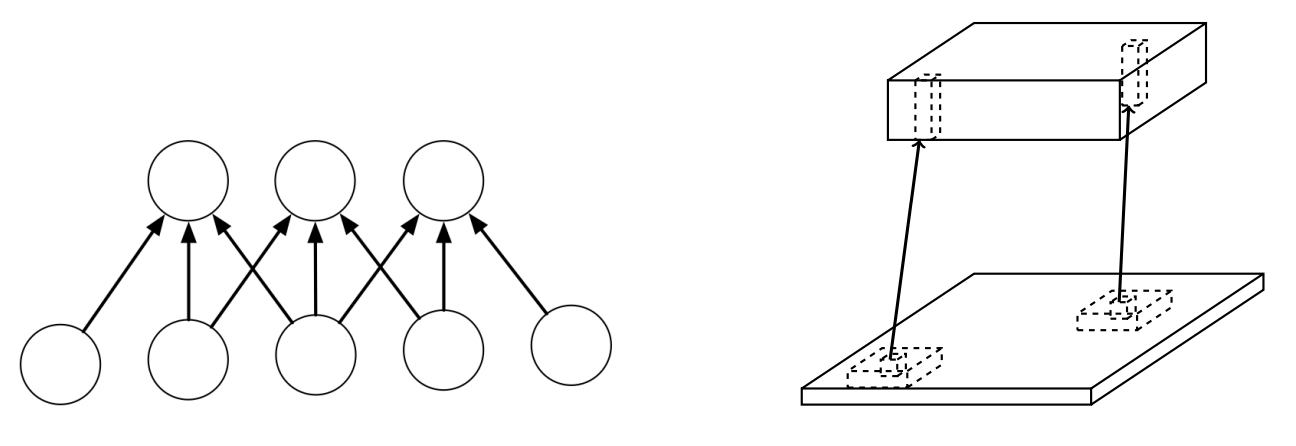
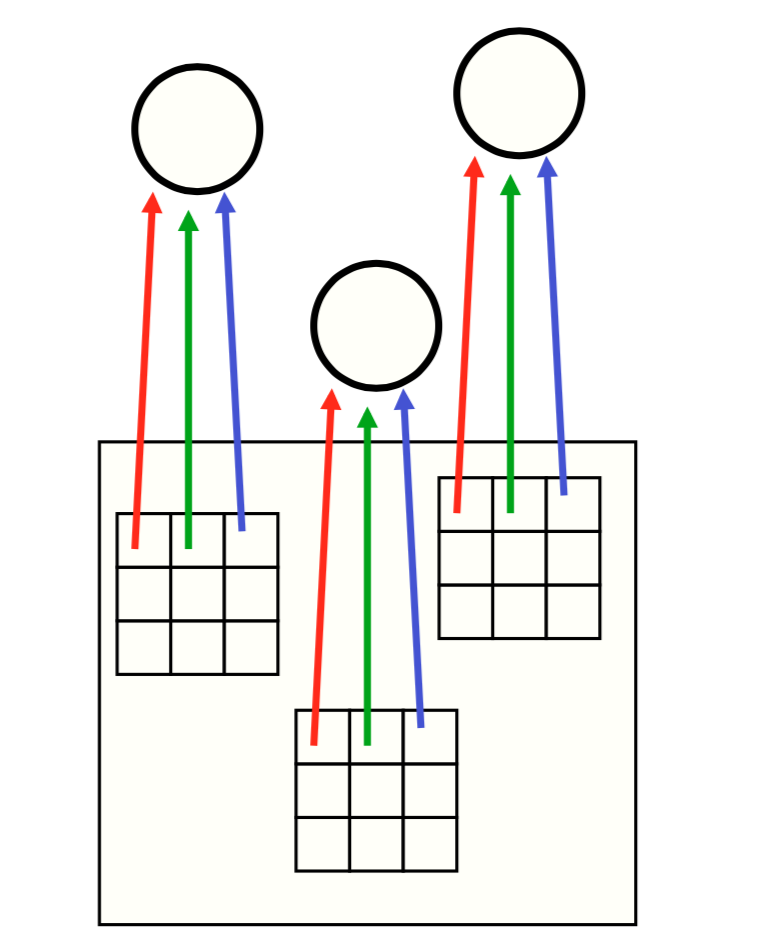
Weight Sharing
Locally connected layers
Convolutional layers
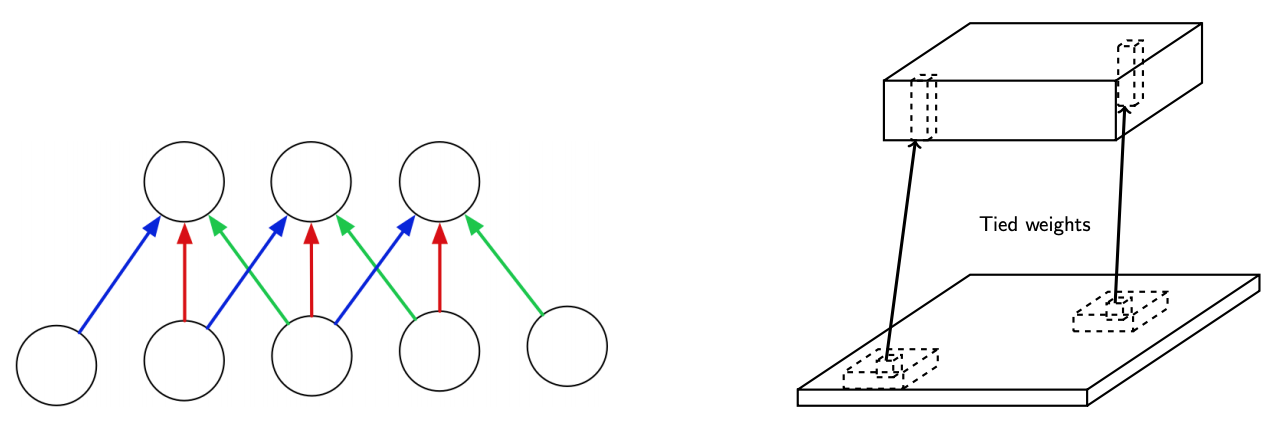
Use the same weights across each region (each colour represents the same weight)
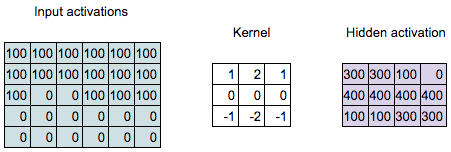
Convolution Computation
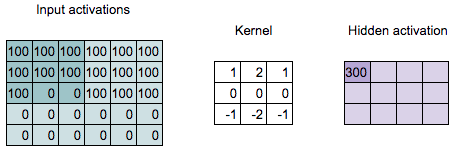
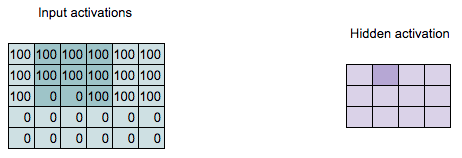
\[\begin{align*} 300 = & 100 \times 1 + 100 \times 2 + 100 \times 1 + \\ & 100 \times 0 + 100 \times 0 + 100 \times 0 + \\ & 100 \times (-1) + 0 \times (-2) + 0 \times (-1) \end{align*}\]
Convolution Computation
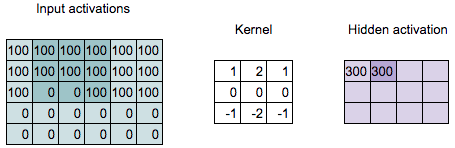
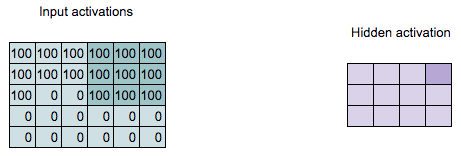
\[\begin{align*} 300 = &100 \times 1 + 100 \times 2 + 100 \times 1 + \\ &100 \times 0 + 100 \times 0 + 100 \times 0 + \\ &0 \times (-1) + 0 \times (-2) + 100 \times (-1) \end{align*}\]
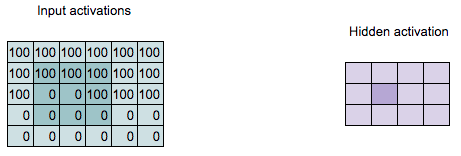
Convolution Computation
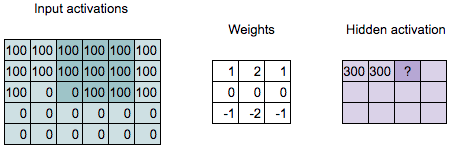
Q: What is the value of the highlighted hidden activation?
Convolution Computation
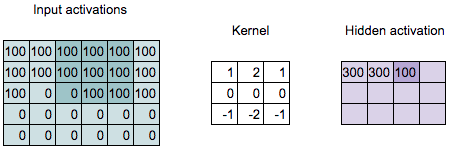
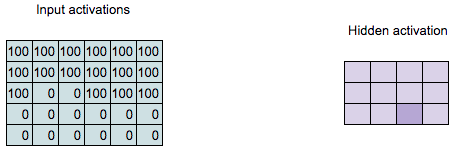
\[\begin{align*} 100 = &100 \times 1 + 100 \times 2 + 100 \times 1 + \\ &100 \times 0 + 100 \times 0 + 100 \times 0 + \\ &0 \times (-1) + 100 \times (-2) + 100 \times (-1) \end{align*}\]
Convolution Computation
Weight Sharing
Each neuron on the higher layer is detecting the same feature, but in different locations on the lower layer
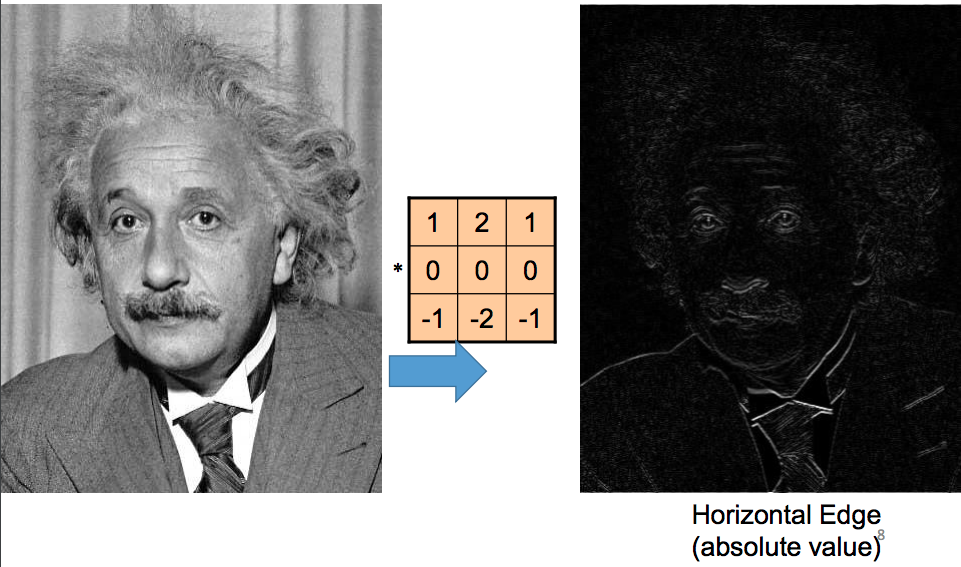
“Detecting” = output (activation) is high if feature is present “Feature” = something in a part of the image, like an edge or shape
Sobel Filter - Weights to Detect Horizontal Edges
Sobel Filter - Weights to Detect Vertical Edges

Weights to Detect Blobs

Q: What is the kernel size of this convolution?
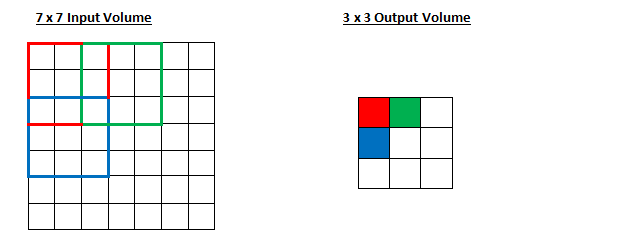
Example:
Greyscale input image: \(7\times 7\)
Convolution kernel: \(3 \times 3\)
Q: How many hidden units are in the output of this convolution?
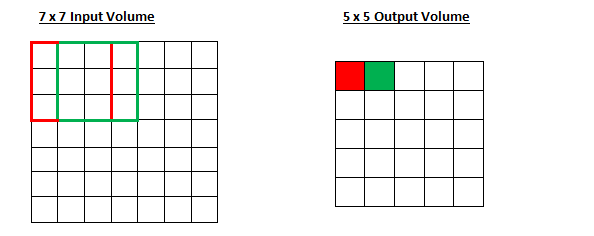
Q: How many trainable weights are there?
There are \(3 \times 3 + 1\) trainable weights (\(+ 1\) for the bias)
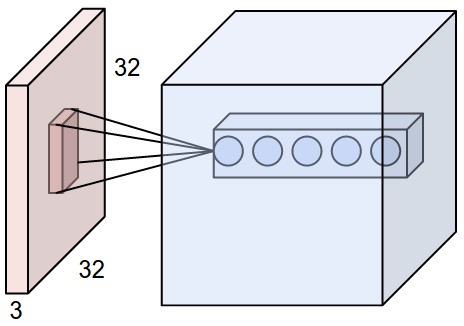
Convolution in RGB
The kernel becomes a 3-dimensional tensor!
In this example, the kernel has size 3 \(\times 3 \times 3\)
Detecting Multiple Features
Q: What if we want to detect many features of the input? (i.e. both horizontal edges and vertical edges, and maybe even other features?)
A: Have many convolutional filters!
Max-Pooling
Idea: take the maximum value in each \(2 \times 2\) grid.
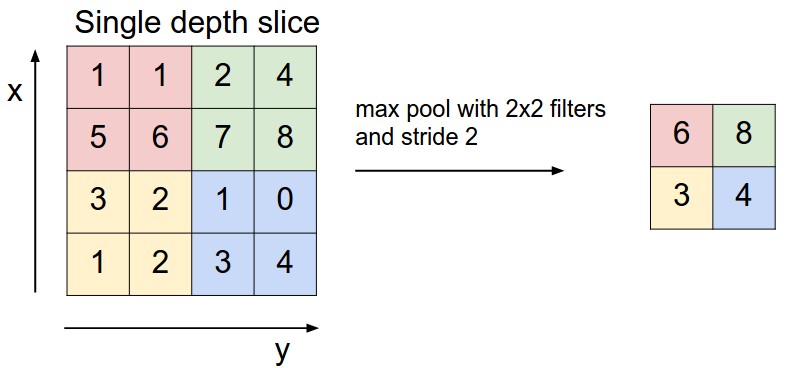
Max-Pooling Example
We can add a max-pooling layer after each convolutional layer
Strided Convolution
More recently people are doing away with pooling operations, using strided convolutions instead:
Shift the kernel by 2 (stride=2) when computing the next output feature.
Multivariate Chain Rule (inputs)
Consider the computation graph for the inputs:
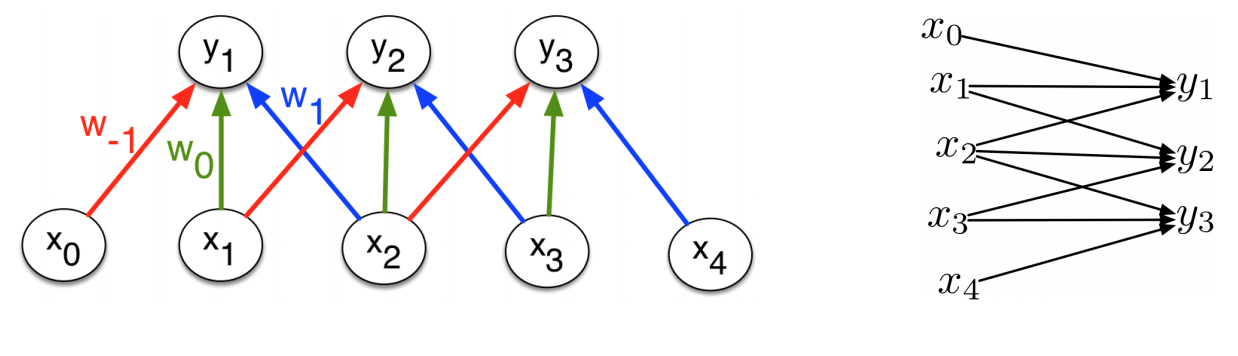
Each input unit influences all the output units that have it within their receptive fields. Using the multivariate Chain Rule, we need to sum together the derivative terms for all these edges
Multivariate Chain Rule (weights)
Consider the computation graph for the weights:
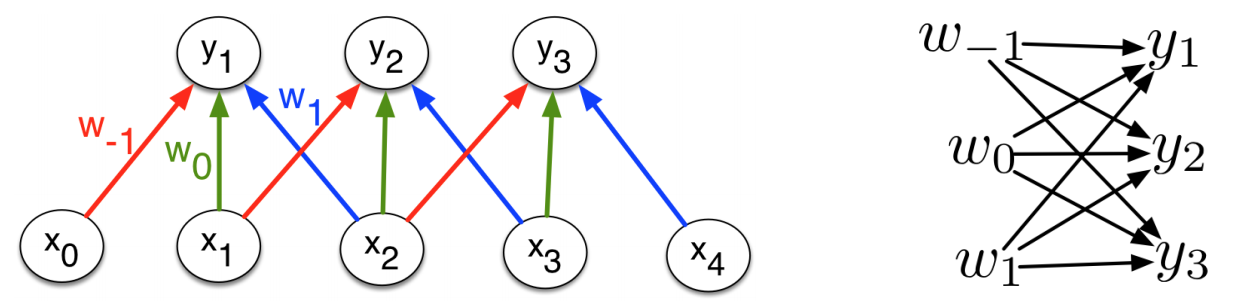
Each of the weights affects all the output units for the corresponding input and output feature maps.
ImageNet I

ImageNet IV

ImageNet V

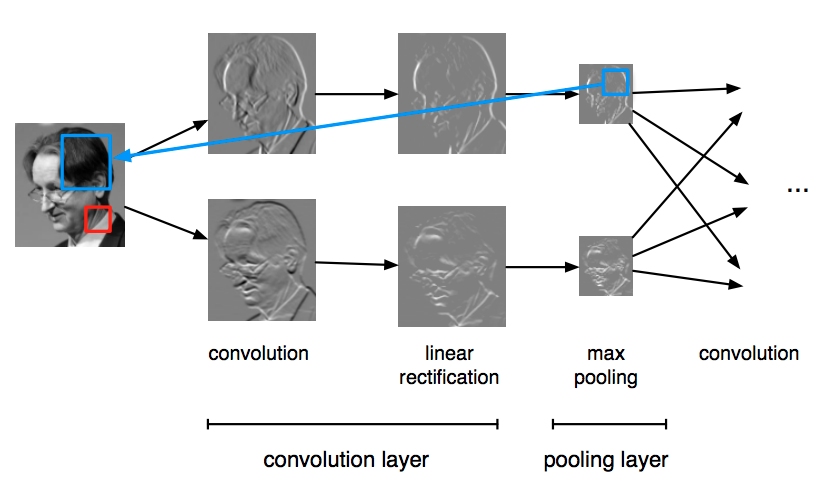
What features do CNN’s detect?

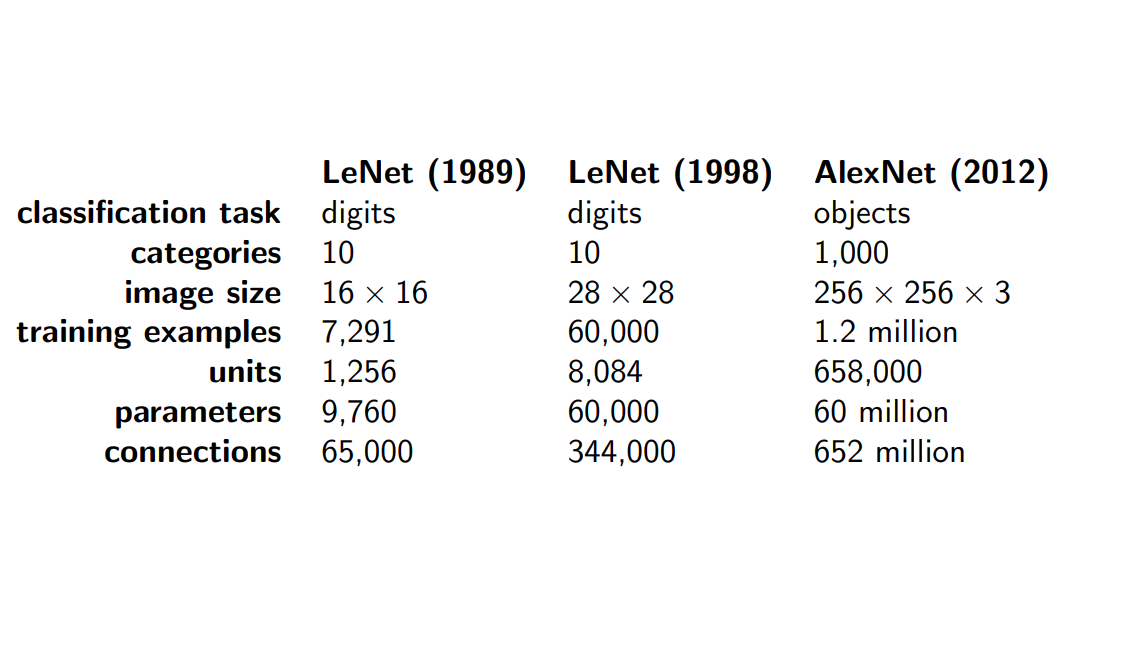
Size of a convnet II
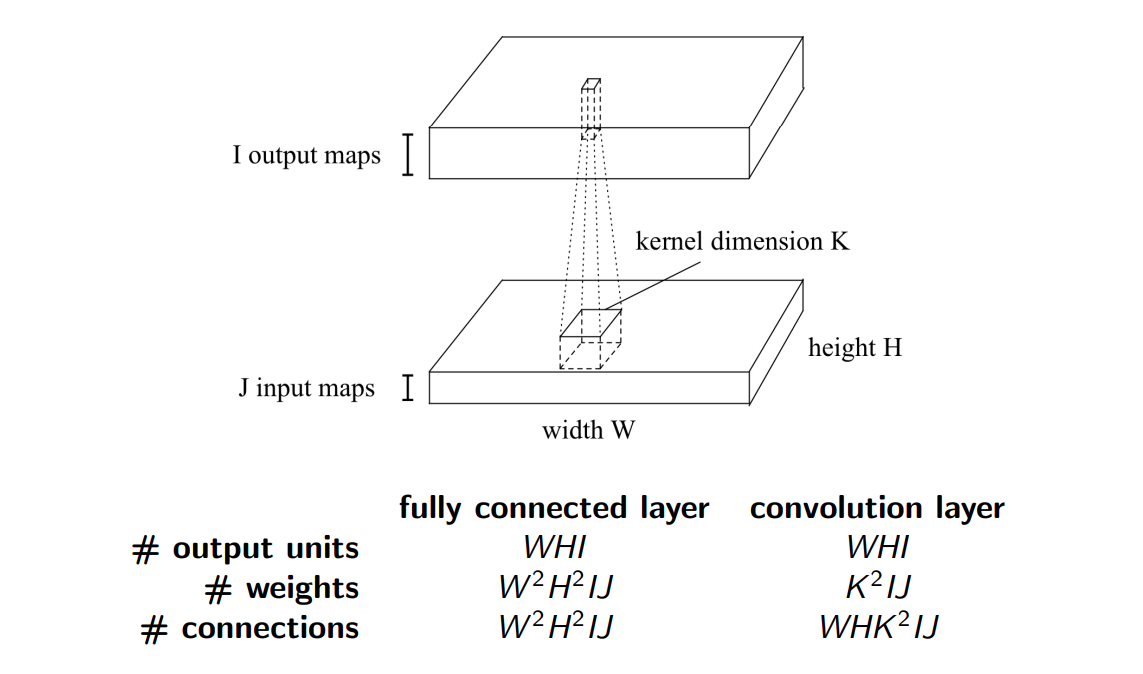
Size of a convnet III
LeNet Atchitecture
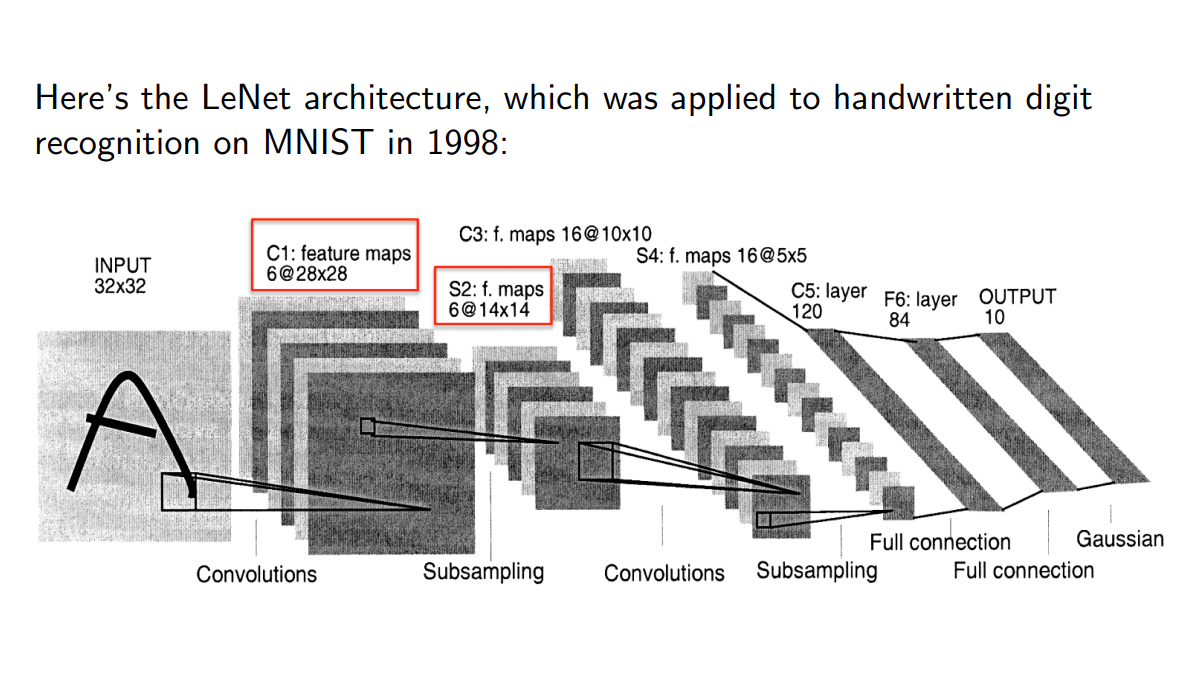
LeNet Architecture II
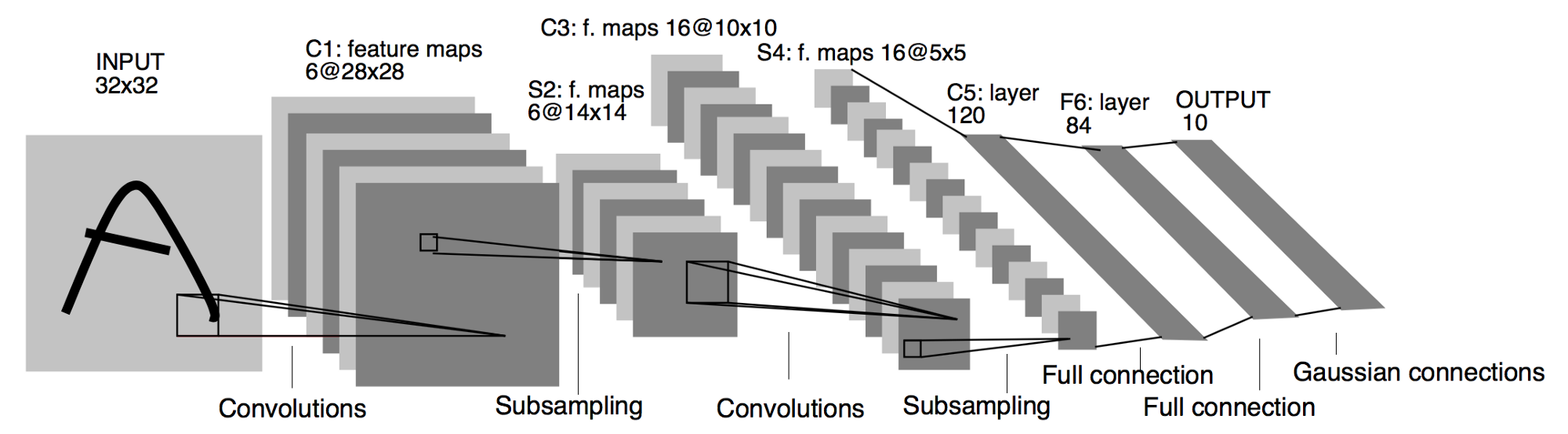
- Input: 32x32 pixel, greyscale image
- First convolution has 6 output features (5x5 convolution?)
- First subsampling is probably a max-pooling operation
- Second convolution has 16 output features (5x5 convolution?)
- …
- Some number of fully-connected layers at the end
ResNet Architecture
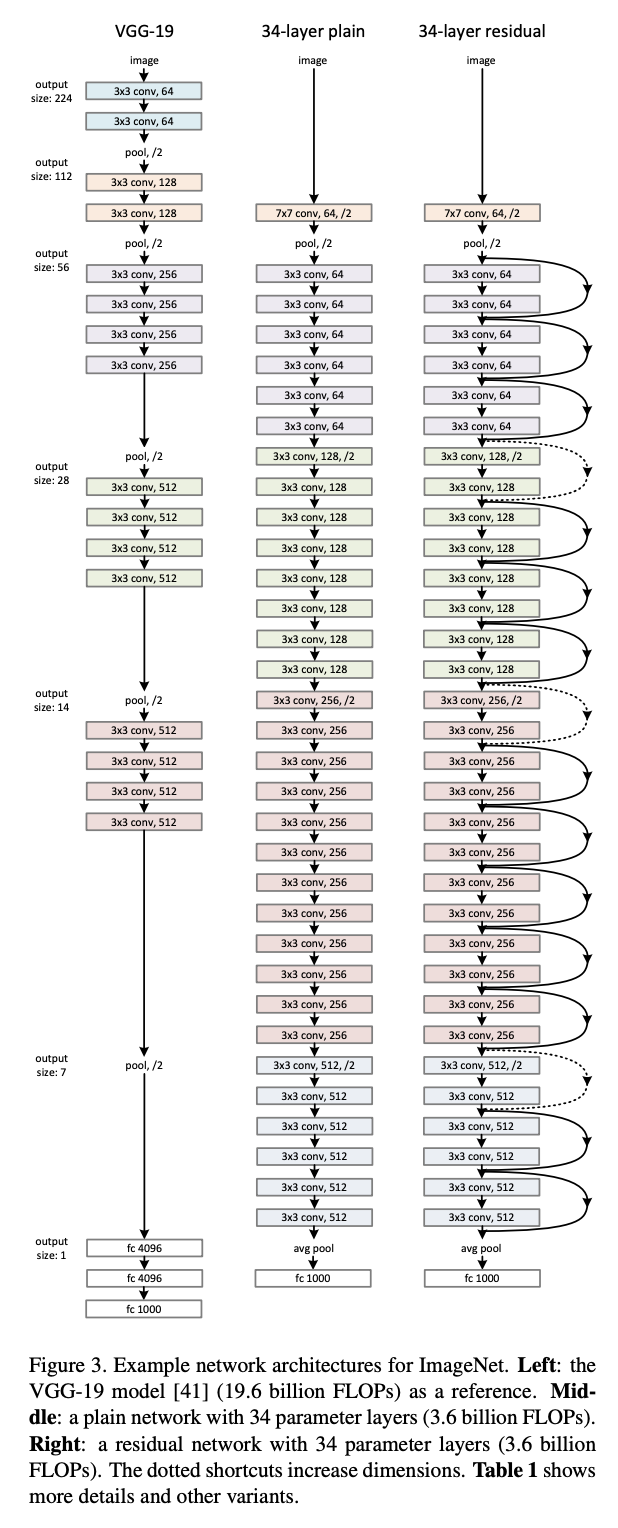
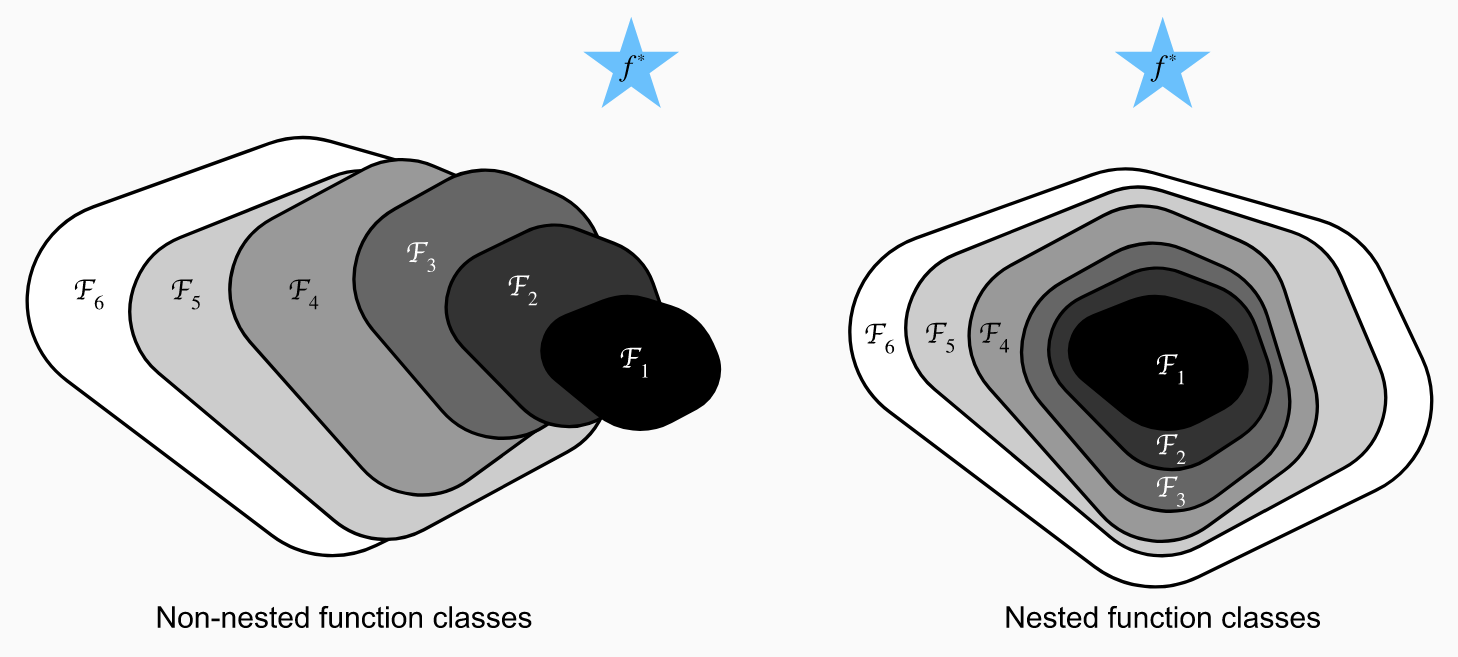
ResNet Blocks
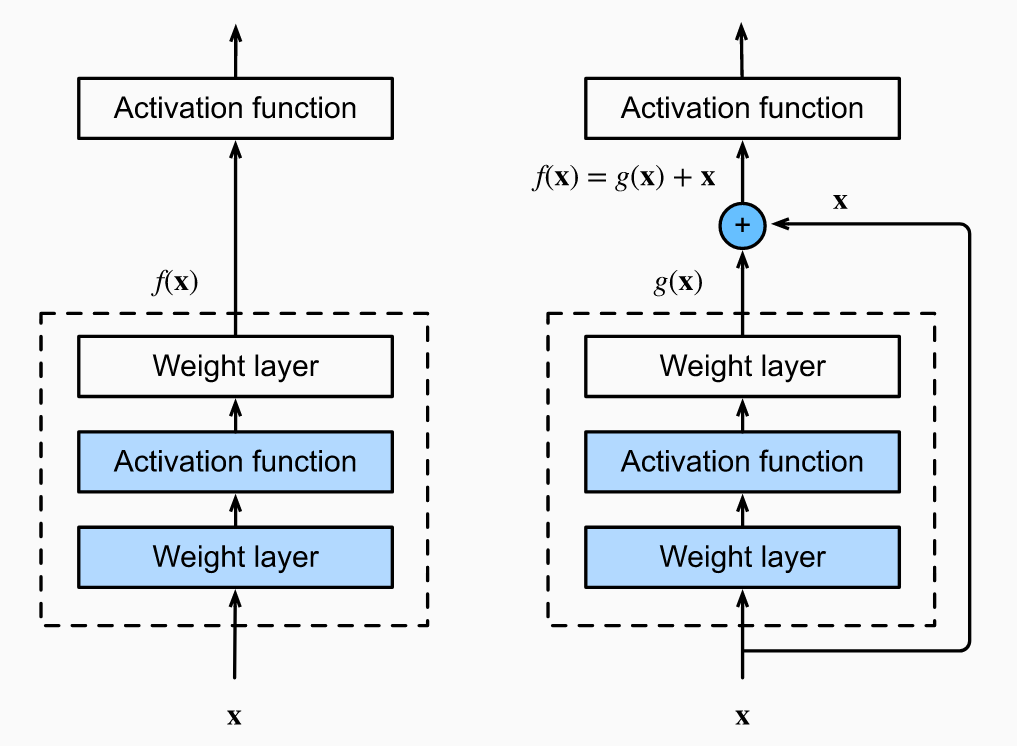
- Side effect of adding identity \(f(x) = x + g(x)\): better gradient propagation
- See https://d2l.ai/chapter_convolutional-modern/resnet.html
DenseNet Blocks
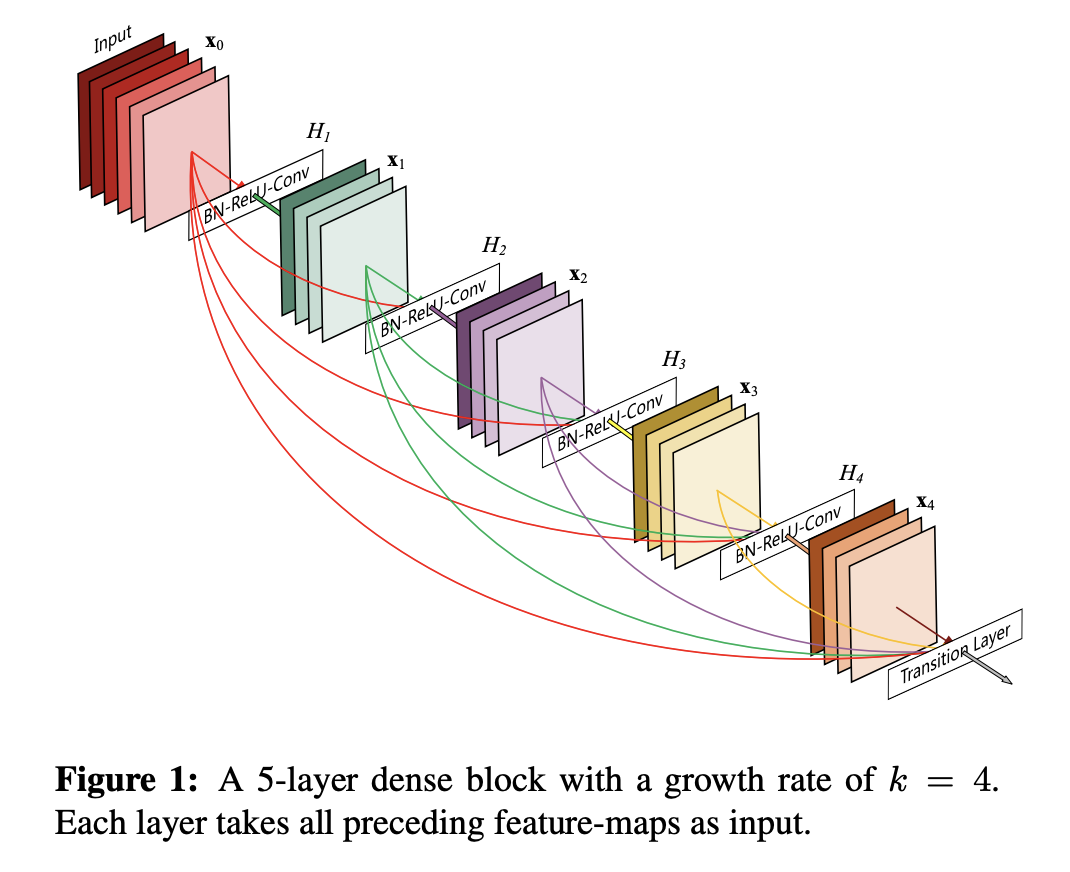
Same idea as ResNet blocks, but instead of addition \(f(x) = x + g(x)\) they use concatenation \(f(x) = [x, g(x)]\).
DenseNet Architecture
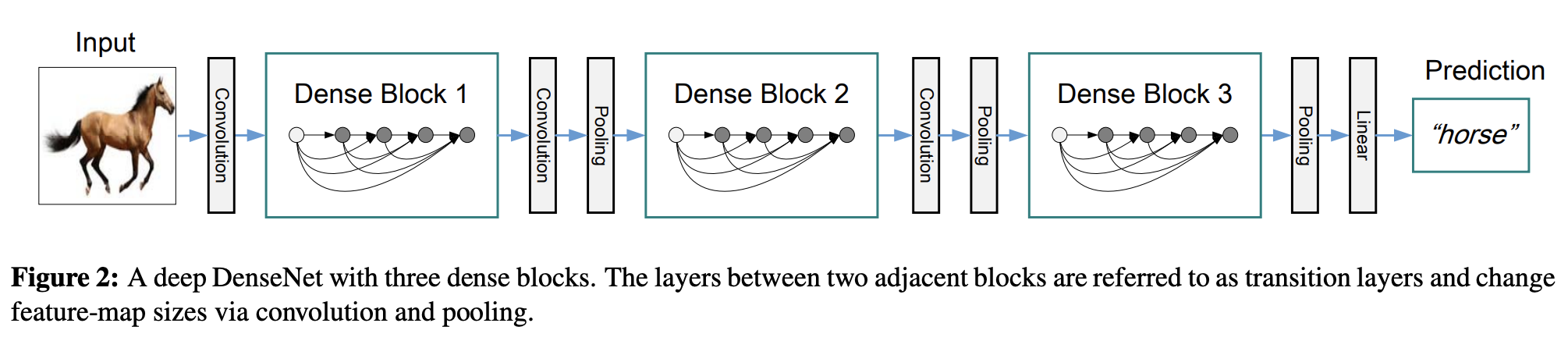
See https://d2l.ai/chapter_convolutional-modern/densenet.html