Recurrent Neural Networks with Attention
Recurrent Neural Networks
In lecture 8, we showed a discriminative RNN that makes a prediction based on a sequence (sequence as an input).
In the week 11 tutorial, we will build a generator RNN to generate sequences (sequence as an output)
Sequence-to-sequence Tasks
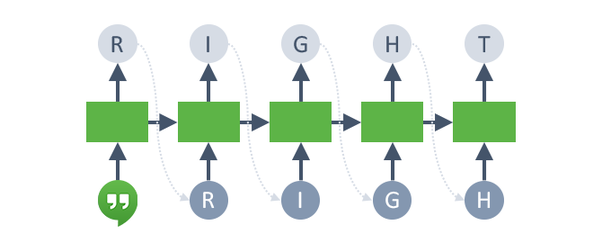
Another common example of a sequence-to-sequence task (seq2seq) is machine translation.
![]()
The network first reads and memorizes the sentences. When it sees the “end token”, it starts outputting the translation. The “encoder” and “decoder” are two different networks with different weights.
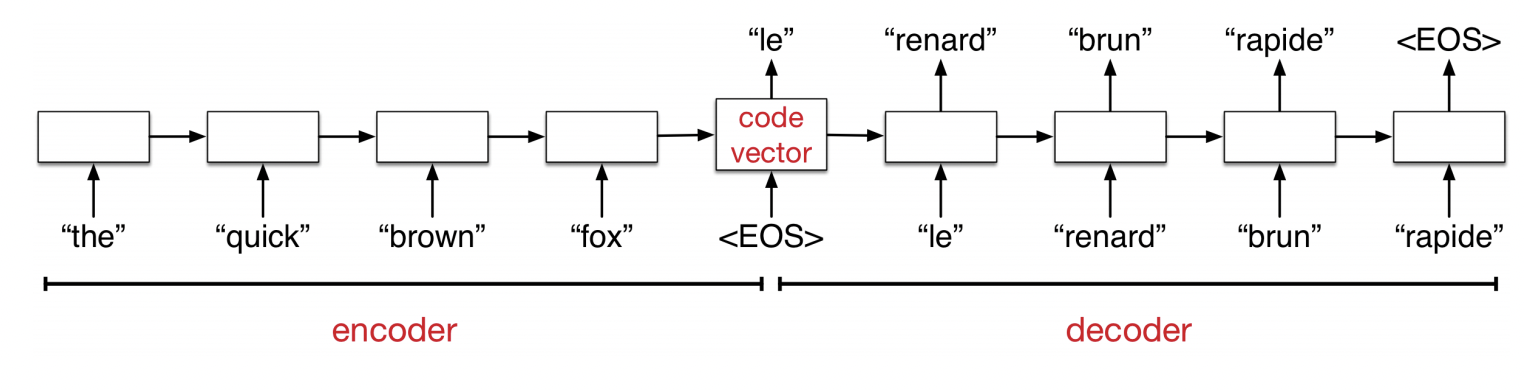
How Seq2Seq Works
The encoder network reads an input sentence and stores all the information in its hidden units.
The decoder network then generates the output sentence one word at a time.
![]()
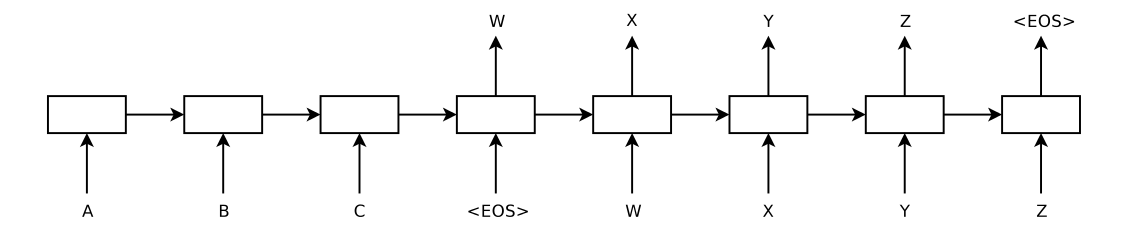
How Seq2Seq Works II
![]()
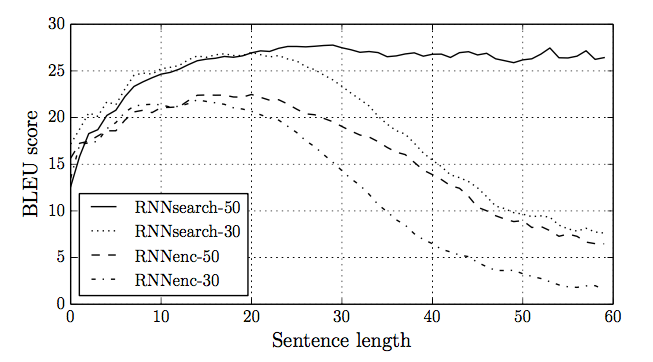
But some sentences can be really long. Can we really store all the information in a vector of hidden units?
Human translators refer back to the input.
Attention-Based Machine Translation
We’ll look at the translation model from the classic paper:
Bahdanau et al., Neural machine translation by jointly learning to align and translate. ICLR, 2015.
Basic idea: each output word comes from one input word, or a handful of input words. Maybe we can learn to attend to only the relevant ones as we produce the output.
We’ll use the opportunity to look at architectural changes we can make to RNN models to make it even more performant.
Encoder & Decoder Architectures
The encoder computes an annotation (hidden state) of each word in the input.
- The encoder is a bidirectional RNN
The decoder network is also an RNN, and makes predictions one word at a time.
- The decoder uses an attention mechanism (RNN with attention)
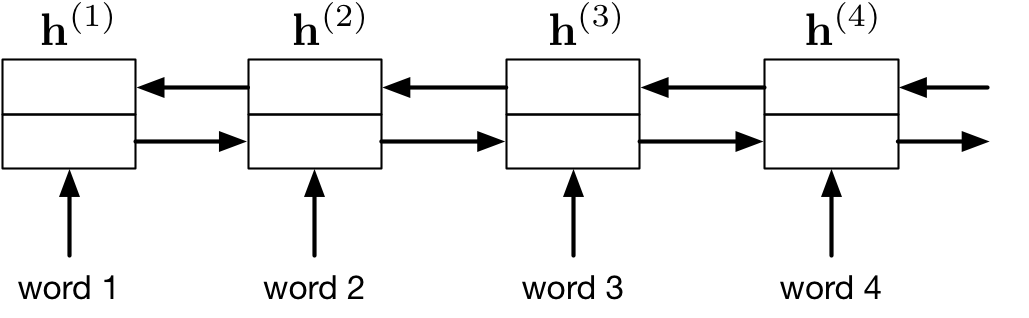
Encoder: Bidirectional RNN
The encoder is a bidirectional RNN. We have two RNNs: one that runs forward and one that runs backwards. These RNNs can be LSTMs or GRUs.
The annotation of a word is the concatenation of the forward and backward hidden vectors.
![]()
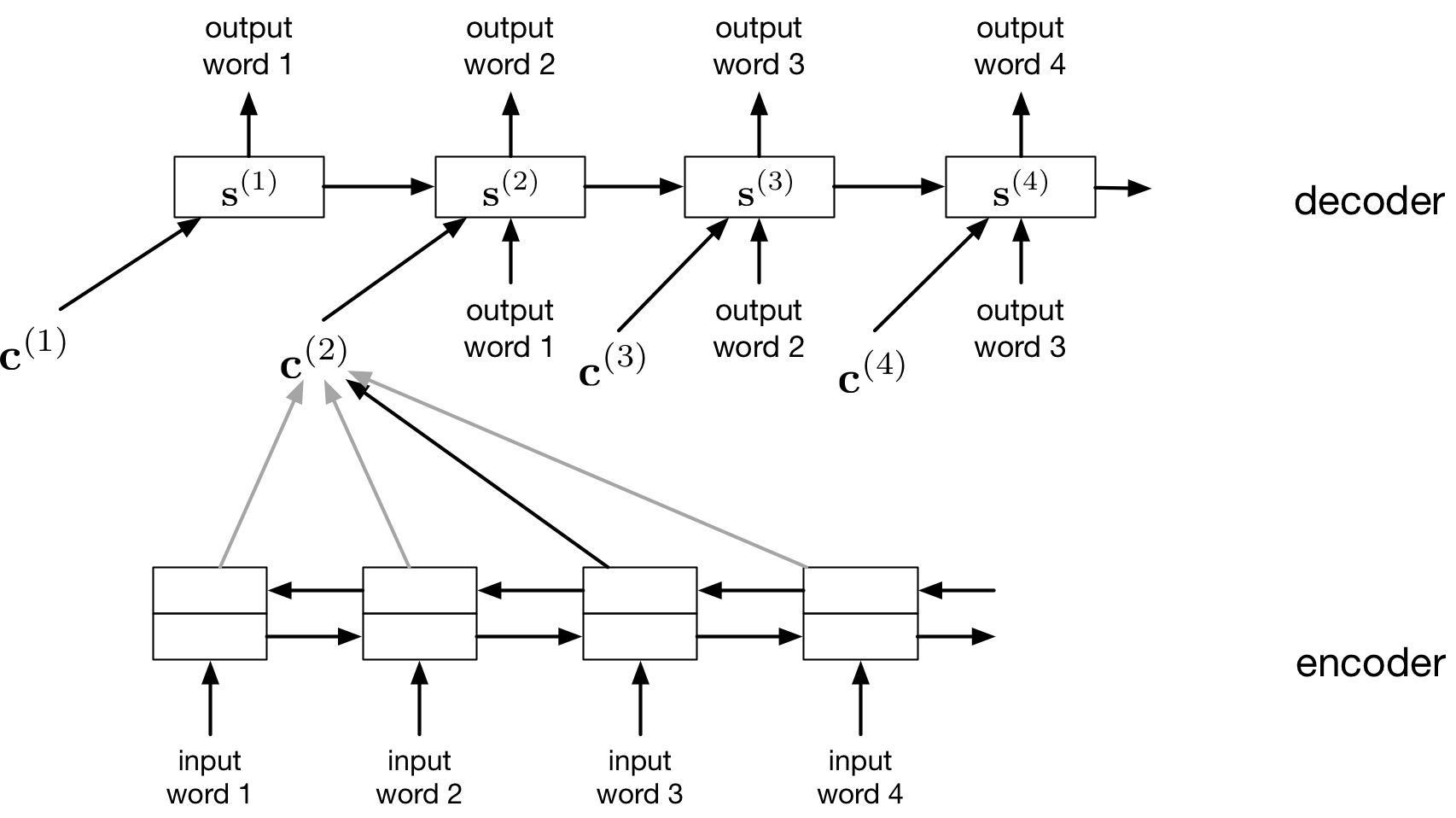
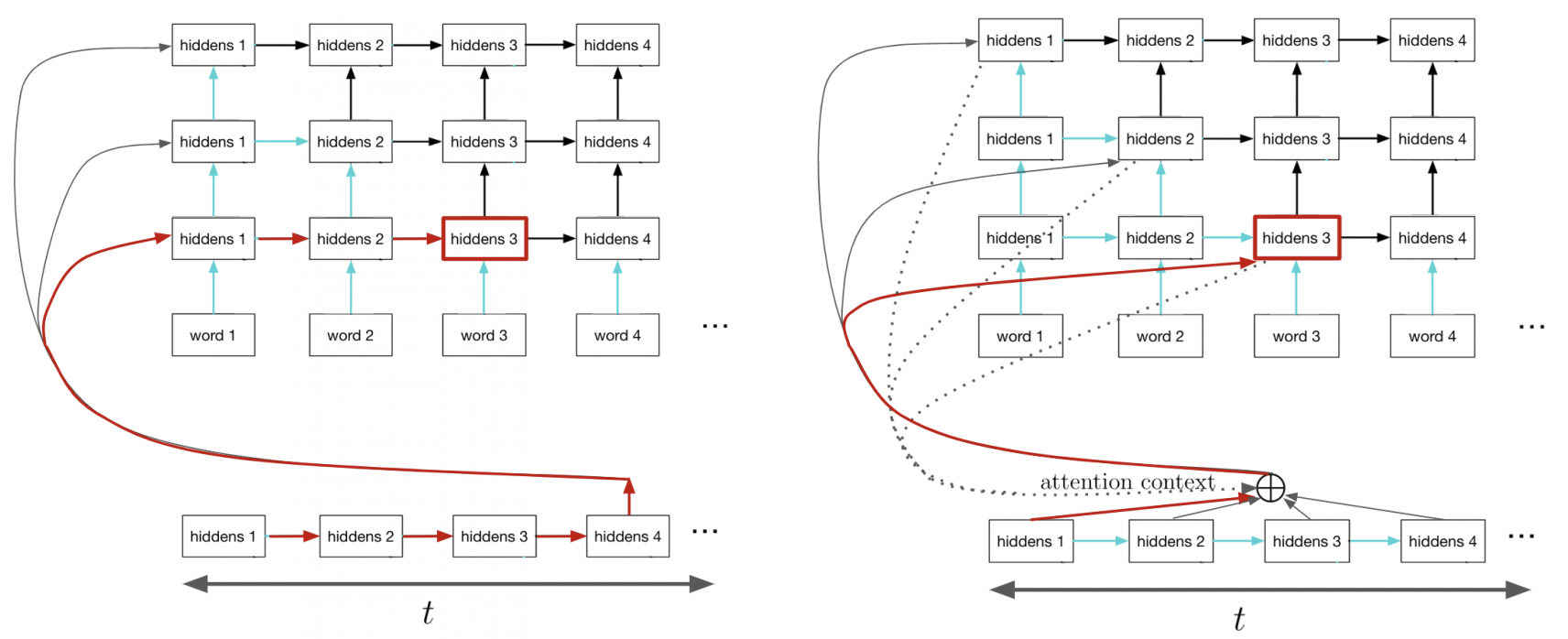
Decoder: RNN with Attention
The decoder network is also an RNN, and makes predictions one word at a time.
The difference is that it also derives a context vector \({\bf c}^{(t)}\) at each time step, computed by attending to the inputs
Example: How to Obtain a Context Vector?
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
{\bf c}^{(t)} &= \begin{bmatrix}? & ? & ?\end{bmatrix}^\top \\
\end{align*}\]
Example: Average Pooling is Context Independent
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
{\bf c}^{(t)} &= \text{average}({\bf h}^{(1)} , {\bf h}^{(2)}, {\bf h}^{(3)})\\
&= \begin{bmatrix}2 & 0.6 & 1\end{bmatrix}^\top \\
\end{align*}\]
Example: Attention
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
{\bf s}^{(t-1)} &= \begin{bmatrix}0 & 1 & 1\end{bmatrix}^\top \\
\alpha_t &= \text{softmax}\left(\begin{bmatrix}
f({\bf s}^{(t-1)}, {\bf h}^{(1)}) \\
f({\bf s}^{(t-1)}, {\bf h}^{(2)}) \\
f({\bf s}^{(t-1)}, {\bf h}^{(3)}) \\
\end{bmatrix}\right) = \begin{bmatrix}\alpha_{t1} \\ \alpha_{t2} \\ \alpha_{t3}\end{bmatrix}
\end{align*}\]
Example: Dot-Product Attention
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
{\bf s}^{(t-1)} &= \begin{bmatrix}0 & 1 & 1\end{bmatrix}^\top \\
\alpha_t &= \text{softmax}\left(\begin{bmatrix}
{\bf s}^{(t-1)} \cdot {\bf h}^{(1)} \\
{\bf s}^{(t-1)} \cdot {\bf h}^{(2)} \\
{\bf s}^{(t-1)} \cdot {\bf h}^{(3)} \\
\end{bmatrix}\right) = \begin{bmatrix}\alpha_{t1} \\ \alpha_{t2} \\ \alpha_{t3}\end{bmatrix}
\end{align*}\]
Example: Dot-Product Attention II
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \qquad \quad {\bf s}^{(t-1)} = \begin{bmatrix}0 & 1 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
\alpha_t &= \text{softmax}\left(\begin{bmatrix}1 & 0 & 5 \\ 3 & 0 & -1 \\ 0 & 1 &2 \end{bmatrix}^\top
\begin{bmatrix}0 \\ 1 \\ 1\end{bmatrix}\right) \\
{\bf c}^{(t)} &= \alpha_{t1} {\bf h}^{(1)} + \alpha_{t2} {\bf h}^{(2)} + \alpha_{t2} {\bf h}^{(3)}\\
\end{align*}\]
Visualization of Attention
Visualization of the attention map (the \(\alpha_{ij}\)s at each time step)
![]()
Nothing forces the model to go (roughly) linearly through the input sentences, but somehow it learns to do it!
Attention-Based Caption Generation
Caption Generation Task:
- Output: Caption (sequence of words or characters)
Attention-Based Caption Generation II
Attention can also be used to understand images.
- We humans can’t process a whole visual scene at once.
- The fovea of the eye gives us high-acuity vision in only a tiny region of our field of view.
- Instead, we must integrate information from a series of glimpses.
Attention-Based Caption Generation III
The next few slides are based on this paper from the UofT machine learning group:
Xu et al. Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention. ICML, 2015.
Attention for Caption Generation
The caption generation task: take an image as input, and produce a sentence describing the image.
- Encoder: a classification conv net like VGG. This computes a bunch of feature maps over the image.
Attention for Caption Generation II
- Decoder: an attention-based RNN, analogous to the decoder in the translation model
- In each time step, the decoder computes an attention map over the entire image, effectively deciding which regions to focus on.
- It receives a context vector, which is the weighted average of the convnet features.
Attention for Caption Generation III
Similar math as before: difference is that \(j\) is a pixel location
\[\begin{align*}
e_{ij} &= a({\bf s}^{(i-1)}, {\bf h}^{(j)}) \\
\alpha_{ij} &= \frac{ \exp(e_{ij}) }{\sum_{j^\prime} exp(e_{ij^\prime})}
\end{align*}\]
What Attention tells us
This lets us understand where the network is looking as it generates a sentence.
![]()
![]()
What Attention tells us about mistakes
This can also help us understand the network’s mistakes.
![]()
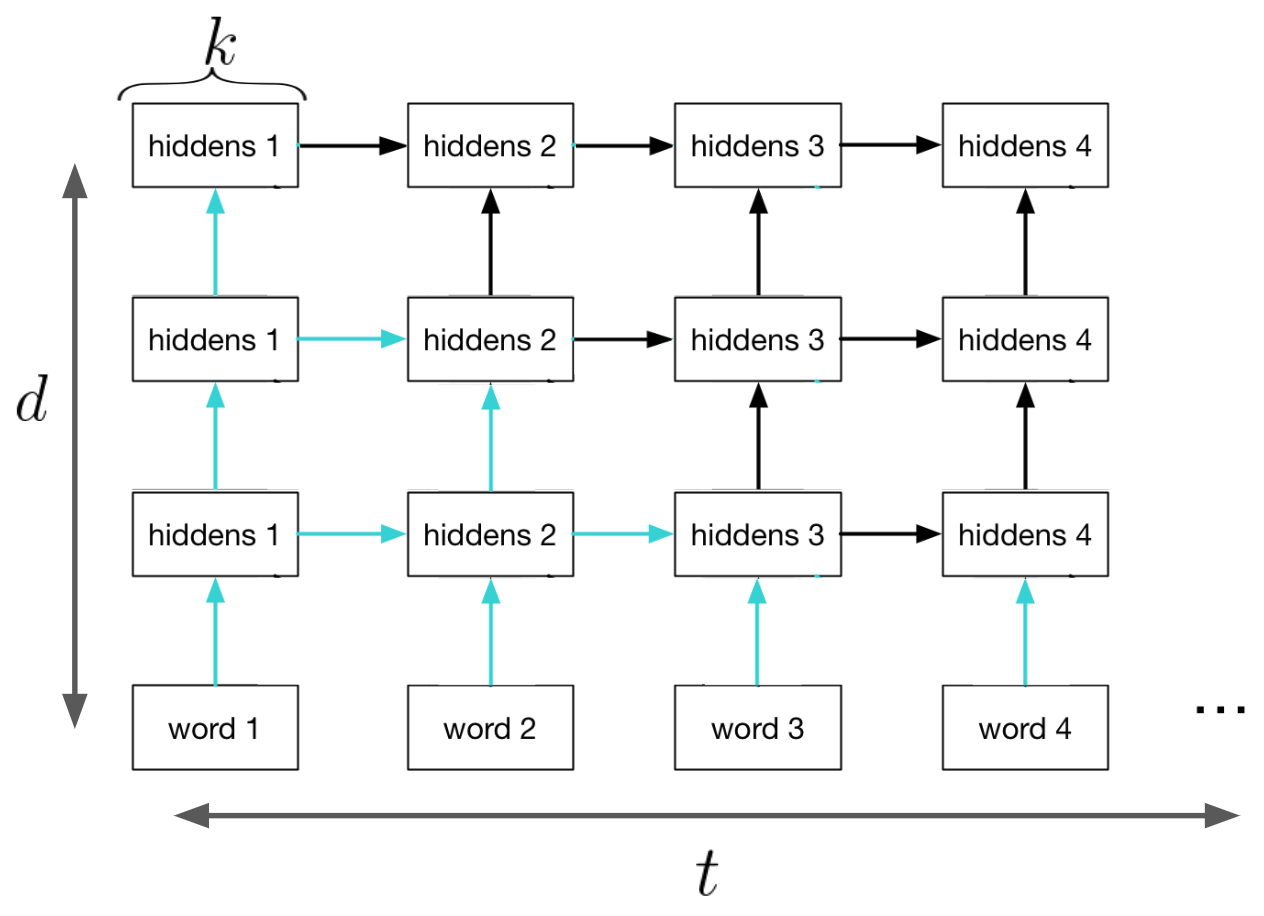
Multi-Layer RNNs
Finally, to get more capacity/performance out of RNNs, you can stack multiple RNN’s together!
The hidden state of your first RNN becomes the input to your second layer RNN.
![]()
RNN Disadvantage
One disadvantage of RNNS (and especially multi-layer RNNs) is that they require a long time to train, and are more difficult to parallelize. (Need the previous hidden state \(h^{(t)}\) to be able to compute \(h^{(t+1)}\))
ChatGPT II
What is ChatGPT? We’ll let it speak for itself:
I am ChatGPT, a large language model developed by OpenAI. I use machine learning algorithms to generate responses to questions and statements posed to me by users. I am designed to understand and generate natural language responses in a variety of domains and topics, from general knowledge to specific technical fields. My purpose is to assist users in generating accurate and informative responses to their queries and to provide helpful insights and suggestions.
ChatGPT III
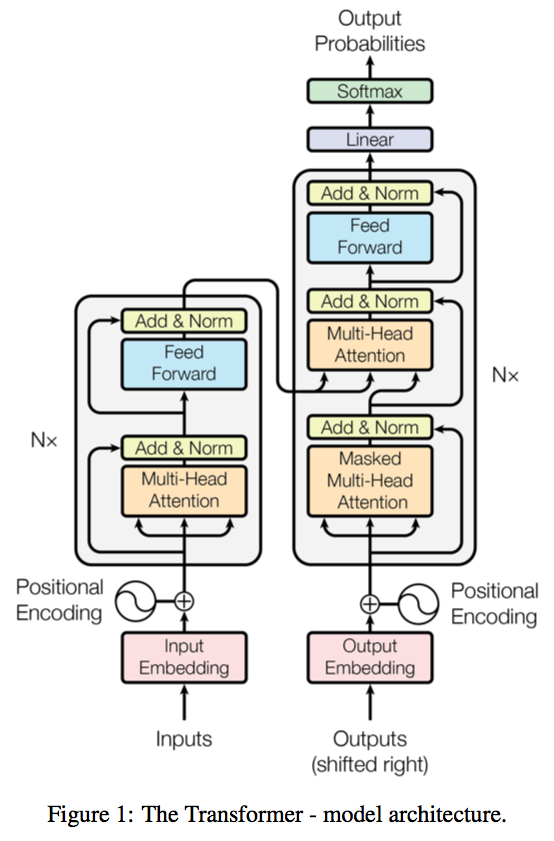
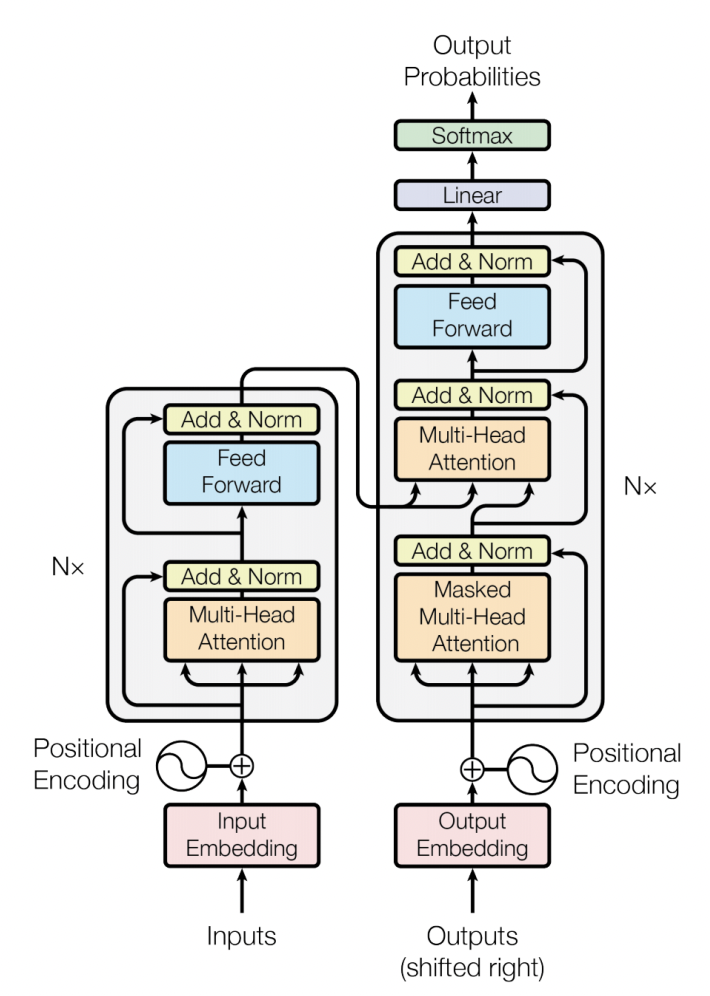
ChatGPT is based on OpenAI’s GPT-3, which itself is based on the transformer architecture.
Vaswani, Ashish, et al. Attention is all you need.
Transformer has a encoder-decoder architecture similar to the previous sequence-to-sequence RNN models, except all the recurrent connections are replaced by the attention modules.
Attention Mapping
In general, attention mapping can be described as a function of a query and a set of key-value pairs. Transformer uses a “scaled dot-product attention” to obtain the context vector:
\[\begin{align*}
{\bf c}^{(t)} = \text{attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_K}}\right) V
\end{align*}\]
This is very similar to the attetion mechanism we saw eariler, but we scale the pre-softmax values (the logits) down by the square root of the key dimension \(d_K\).
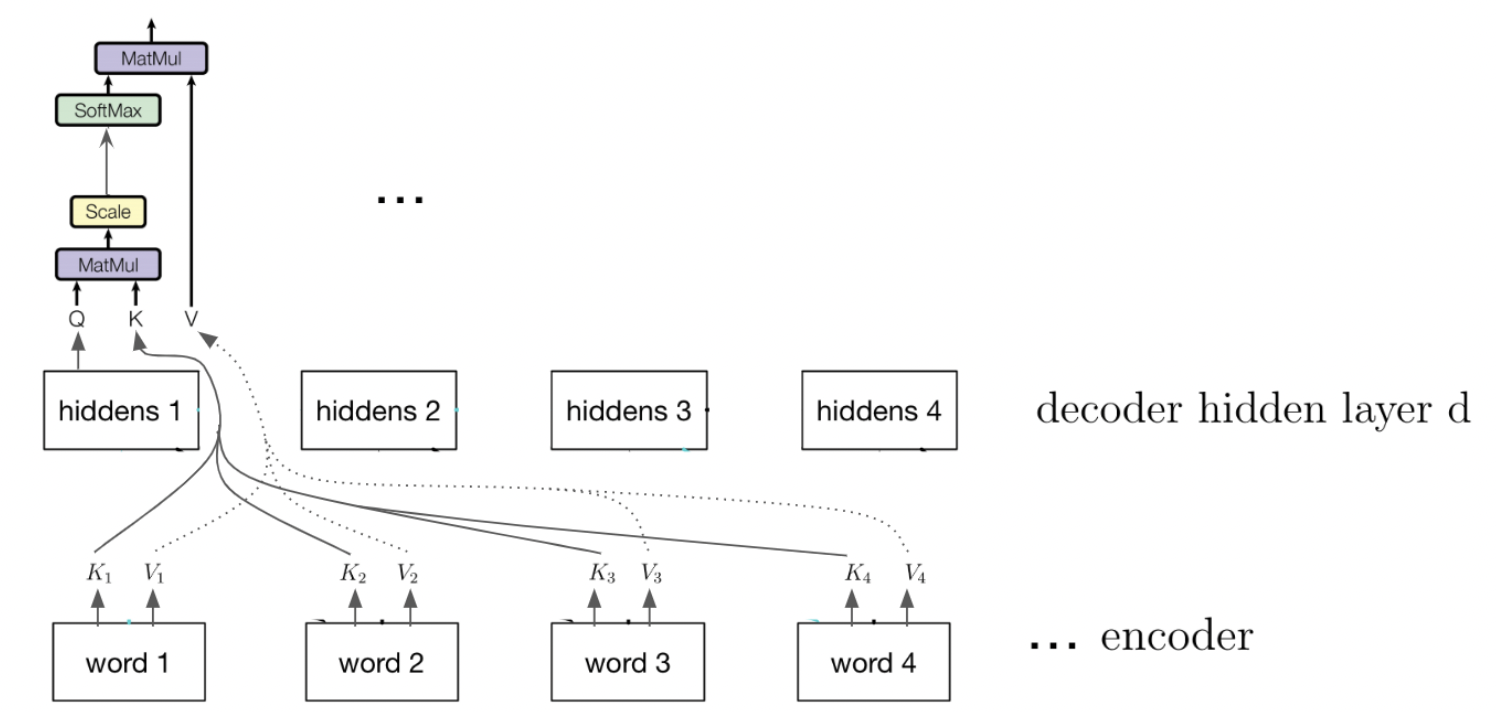
Attention Mapping in the Decoder
When training the decoder (e.g. to generate a sequence), we desired output so that have to be careful to mask out the desired output so that we preserve the autoregressive property.
![]()
Recall: Dot-Product Attention
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \\
{\bf h}^{(2)} &= \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \qquad \quad {\bf s}^{(t-1)} = \begin{bmatrix}0 & 1 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \\
\\
\alpha_t &= \text{softmax}\left(\begin{bmatrix}1 & 0 & 5 \\ 3 & 0 & -1 \\ 0 & 1 &2 \end{bmatrix}^\top
\begin{bmatrix}0 \\ 1 \\ 1\end{bmatrix}\right) \\
{\bf c}^{(t)} &= \alpha_{t1} {\bf h}^{(1)} + \alpha_{t2} {\bf h}^{(2)} + \alpha_{t2} {\bf h}^{(3)}\\
\end{align*}\]
Scaled Dot-Product Attention
\[\begin{align*}
{\bf h}^{(1)} &= \begin{bmatrix}1 & 3 & 9\end{bmatrix}^\top \qquad \quad {\bf h}^{(2)} = \begin{bmatrix}0 & 0 & 1\end{bmatrix}^\top \\
{\bf h}^{(3)} &= \begin{bmatrix}5 & -1 & 2\end{bmatrix}^\top \qquad \quad {\bf s}^{(t-1)} = \begin{bmatrix}0 & 1 & 1\end{bmatrix}^\top \\
\alpha_t &= \text{softmax}\left(\frac{1}{\sqrt{3}} \begin{bmatrix}1 & 0 & 5 \\ 3 & 0 & -1 \\ 0 & 1 &2 \end{bmatrix}^\top
\begin{bmatrix}0 \\ 1 \\ 1\end{bmatrix}\right) \\
{\bf c}^{(t)} &= \alpha_{t1} {\bf h}^{(1)} + \alpha_{t2} {\bf h}^{(2)} + \alpha_{t2} {\bf h}^{(3)}\\
\end{align*}\] Q: Which values represent the Q, K, and V?
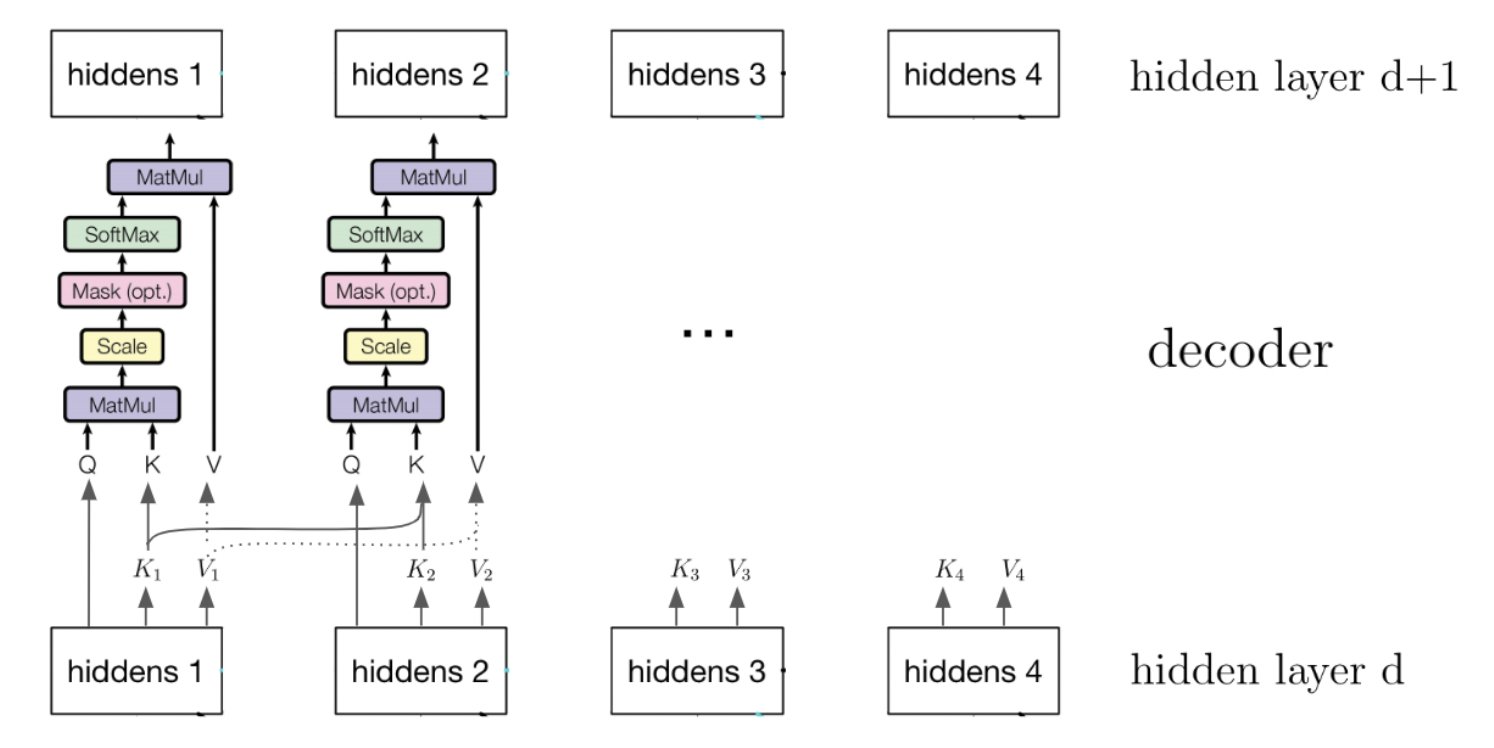
Self-attention
Transformer models also use “self-attention” on its previous hidden layers. When applying attention to the previous hidden layers, the causal structure is preserved:
Multi-headed Attention
The Scaled Dot-Product Attention attends to one or few entries in the input key-value pairs.
But humans can attend to many things simultaneously
Idea: apply scaled dot-product attention multiple times on the linearly transformed inputs:
\[\begin{align*}
\mathbf c_i &= \text{attention}\left(QW_i^Q, KW_i^K, VW_i^V\right) \\
\text{MultiHead}(Q, K, V) &= \text{concat}({\bf c_1}, \dots, {\mathbf c_h})W^O
\end{align*}\]
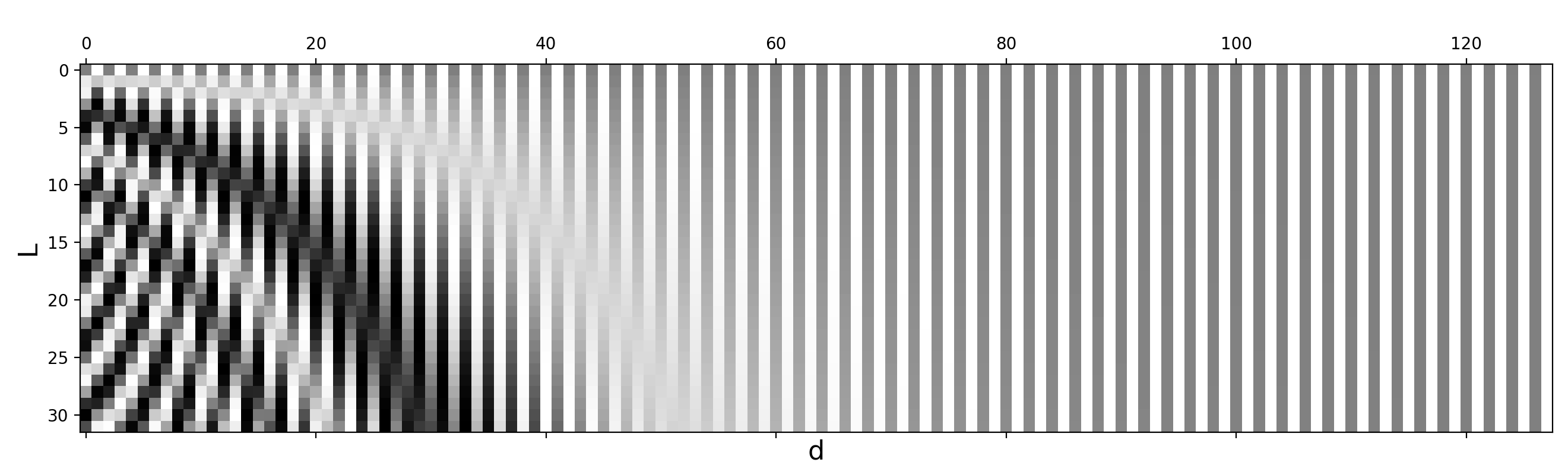
Positional Encoding
Idea: Add positional information of each input token in the sequence into the input embedding vectors.
\[\begin{align*}
PE_{\text{pos}, 2i} &= \sin\left(\text{pos}/10000^{2i/d_{emb}}\right) \\
PE_{\text{pos}, 2i+1} &= \cos\left(\text{pos}/10000^{2i/d_{emb}}\right)
\end{align*}\]
Positional Encoding II
The final input embeddings are the concatenation of the learnable embeddings and the positional encoding.
Backprop
During backprop, in the standard encoder-decoder RNN, the maximum path length across time is the number of time steps.
Backprop II
Attention-based RNNs have a constant path length between the encoder inputs and the decoder hidden states. (Learning becomes easier. Why?)
GPT-3: Generating an Article
Title: United Methodists Agree to Historic Split
Subtitle: Those who oppose gay marriage will form their own denomination
GPT-3: Generating an Article II
Article: After two days of intense debate, the United Methodist Church has agreed to a historic split - one that is expected to end in the creation of a new denomination, one that will be “theologically and socially conservative,” according to The Washington Post. The majority of delegates attending the church’s annual General Conference in May voted to strengthen a ban on the ordination of LGBTQ clergy and to write new rules that will “discipline” clergy who officiate at same-sex weddings. But those who opposed these measures have a new plan: They say they will form a separate denomination by 2020, calling their church the Christian Methodist denomination.
GPT-3: Generating an Article III
The Post notes that the denomination, which claims 12.5 million members, was in the early 20th century the “largest Protestant denomination in the U.S.,” but that it has been shrinking in recent decades. The new split will be the second in the church’s history. The first occurred in 1968, when roughly 10 percent of the denomination left to form the Evangelical United Brethren Church.
GPT-3: Generating an Article IV
The Post notes that the proposed split “comes at a critical time for the church, which has been losing members for years,” which has been “pushed toward the brink of a schism over the role of LGBTQ people in the church.” Gay marriage is not the only issue that has divided the church. In 2016, the denomination was split over ordination of transgender clergy, with the North Pacific regional conference voting to ban the
Brown et al. 2020, Language Models are Few-Shot Learners
GPT-3: Correcting English Grammar
Poor English input: The patient was died.
Good English output: The patient died.
Poor English input: We think that Leslie likes ourselves.
Good English output: We think that Leslie likes us.
Poor English input: Janet broke Bill on the finger.
Good English output: Janet broke Bill’s finger.
Poor English input: Mary arranged for, in St. Louis, John to rent a house cheap.
Good English output: Mary arranged for John to rent a house in St. Louis.
GPT-3: Correcting English Grammar II
Poor English input: Today I have went to the store to to buys some many bottle of water.
Good English output: Today I went to the store to buy some bottles of water.
Poor English input: I have tried to hit ball with bat, but my swing is has miss.
Good English output: I tried to hit the ball with the bat, but my swing missed.
Brown et al. 2020, Language Models are Few-Shot Learners
Large Language Models (LLMs)
Many Transformer-based models have been developed since 2017.
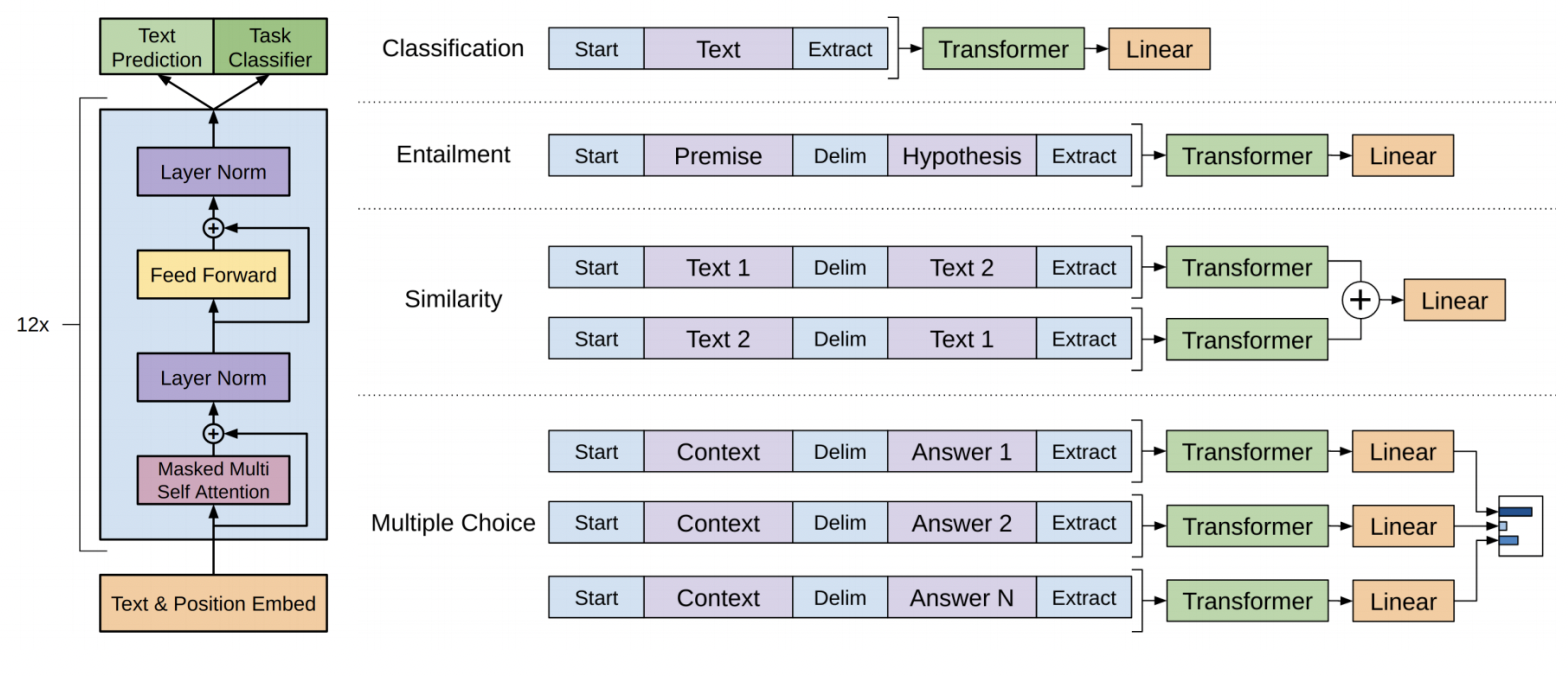
- Generative Pre-Trained Transformer (GPT-1/2/3)
- Decoder-only 12-layer/12-headed Transformer.
- Inspired GPT-Neo, GPT-J, GPT-NeoX, ChatGPT.
- GPT-4 coming out soon.
Large Language Models (LLMs) II
- Bidirectional Encoder Representations from Transformers (BERT)
- Encoder-only 12-layer/12-headed Transformer.
- Inspired ALBERT, RoBERTa, SBERT, DeBERTa, etc.
Large Language Models (LLMs) III
Many benchmarks have been developed such as GLUE and SQuAD.
Big players in the LLM space include Google (Brain, DeepMind), Meta (formerly Facebook, FAIR), Microsoft, Amazon, EleutherAI, OpenAI, Cohere, Hugging Face.